 Redakcja testerzy.pl
Redakcja testerzy.pl


Czy znasz ten wykres pokazujący relatywny koszt naprawy defektów w zależności od fazy, w której zostały one znalezione?
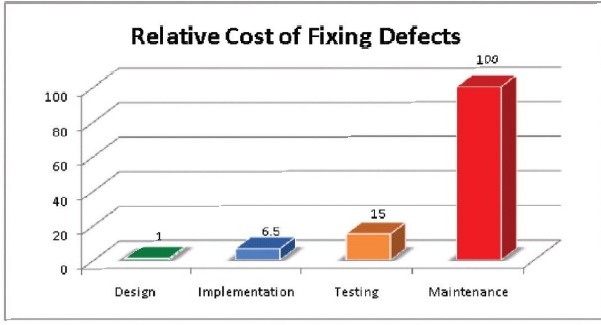 Pochodzi z publikacji "Relative Costs to Fix Software Defects" (Źródło: IBM Systems Sciences Institute), a czas jego powstania nie jest dokładnie znany. Prawdopodobnie publikacja ma 20+ lat.
Pochodzi z publikacji "Relative Costs to Fix Software Defects" (Źródło: IBM Systems Sciences Institute), a czas jego powstania nie jest dokładnie znany. Prawdopodobnie publikacja ma 20+ lat.
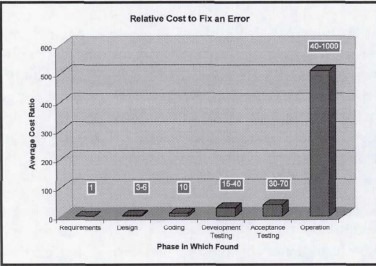
A może natrafiłeś na taką wizualizację? Interesuje nas czerwona krzywa pokazująca koszty naprawy defektów.
 Jest to opracowanie bazujące na danych pochodzących z książki Caspera Jonesa "Applied Software Measurement" z 1991 roku, a sam wykres powstał już później.
Jest to opracowanie bazujące na danych pochodzących z książki Caspera Jonesa "Applied Software Measurement" z 1991 roku, a sam wykres powstał już później.
A te wykresy coś Ci mówią?
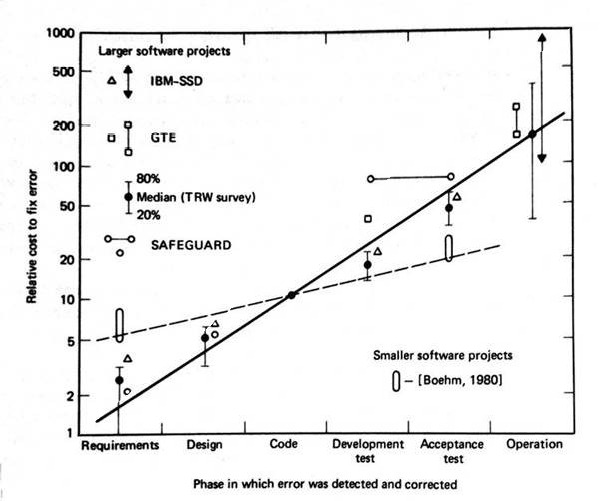 Opublikował je Barry Boehm w swojej książce "Software Engineering Economics" wydanej pierwotnie w 1981 roku.
Opublikował je Barry Boehm w swojej książce "Software Engineering Economics" wydanej pierwotnie w 1981 roku.
Wszystkie one pokazują mniej więcej to samo – ile będzie kosztowało naprawienie defektu w projekcie w zależności od tego kiedy został on znaleziony. Jednocześnie wszystkie wykresy są tak stare, że nadają się jedynie do muzeum informatyki.
Oto 6 powodów, dla których powinniśmy usunąć je ze swoich slajdów lub też postawić przy nich dużą gwiazdkę z informacją, że są to dane historyczne z niewielkim przełożeniem na współczesne projekty:
- To jest wiedza z głębokiej przeszłości. Wykres "koszt naprawy defektów" został opublikowany ponad 40 lat temu, a dane źródłowe, które stanowią podstawę do analizy, mogą mieć już prawie 50 lat. Dla projektów informatycznych to coś więcej niż epoka, to jak czytanie starych ksiąg upadłej cywilizacji.
- To jest wiedza z zupełnie innego modelu wytwórczego. W tamtych latach większość projektów prowadzonych było kaskadowo, a o szybkiej pętli zwrotnej oraz o iteracyjności w produkcji oprogramowania nawet nie myślano. Tworzenie kodu było wysublimowaną sztuką inżynieryjną. W dobie Agile oprogramowanie tworzy się zupełnie inaczej.
- To jest wiedza z zupełnie innego kontekstu. Analizy źródłowe dotyczą dużych, amerykańskich projektów informatycznych dla oprogramowania desktopowego i wbudowanego ze złożonymi strukturami i rozbudowaną biurokracją. Jeśli pracujesz w małym startupie i na technologiach webowych, to te dane nie mają u Ciebie zastosowania.
- To jest wiedza z zupełnie innych technologii. Języki, jakie w czasach publikacji tych danych brano pod uwagę, to Assembler, C, CHILL, PASCAL, Ada, C++, Small Talk. Więc jeśli testujesz produkt napisany w jednym z tych języków to masz szansę, że przynajmniej częściowo te dane dotyczą twojego projektu.
- To jest wiedza, która wymaga szczególnego opisania, aby była zrozumiała. Niewiele osób rozumie czym są te wykresy. Jest to koszt naprawienia problemu, który pojawił się w fazie wymagań i przecieka nienaprawiony do kolejnych faz. Im później zostanie znaleziony, tym droższy jest w naprawieniu. Nie jest więc tak, że każda poprawka defektu znalezionego w fazie kodowania będzie droższa od defektu z fazy wymagań. Jeśli defekt został wprowadzony w fazie kodowania i tam naprawiony, to jego koszt wcale nie musi być dużo.
- To jest wiedza z tzw. "najlepszych praktyk". Dane z innego projektu mają zerowe zastosowanie do Twojego projektu. Jest zbyt wiele zmiennych aby stwierdzić, że jeśli w innym projekcie koszt naprawy defektu wyniósł 100 jednostek, to u Ciebie będzie to też około 100 jednostek.
Każdy z powyższych powodów sam jeden wystarczy do tego, by wyrzucić ze swojej bazy wiedzy informacje o tym "ile kosztuje defekt". Z drugiej strony jest to na tyle znany wykres i na tyle uznany, że powszechnie używa się go do uzasadniania testowania oprogramowania. Jednocześnie jest tak bardzo nieaktualny, że w dyskusji z każdym średnio rozgarniętym kierownikiem projektu lub klientem pęknie przy pierwszym naporze kontrargumentów. Jeśli chcesz go używać, to musisz być w stanie również go obronić. A to nie jest proste.











