Redakcja
Redakcja


CrowdStrike, firma z siedzibą w Austin w Teksasie, znana z ochrony systemów komputerowych przed hakerami, nieświadomie stała się przyczyną nowej, „największej w historii” awarii IT. Błąd w ich oprogramowaniu Falcon Sensor, używanym przez setki tysięcy komputerów na całym świecie, spowodował masowe zawieszanie się systemów Windows i niekończące się cykle restartów, dotykając branże od lotnictwa po służbę zdrowia.
Skala problemu była ogromna: linie lotnicze uziemiły samoloty, szpitale odwoływały operacje, a systemy ratunkowe w wielu krajach przestały działać. Ta sytuacja boleśnie uwidoczniła, jak bardzo współczesny świat jest zależny od sprawnie działającej infrastruktury cyfrowej i jak krucha może być ta zależność.
Awaria krok po kroku
W ubiegły czwartek (18.07.2024) CrowdStrike rozpoczęła dystrybucję rutynowej aktualizacji swojego oprogramowania Falcon Sensor. Jej celem była poprawa wydajności i wprowadzenie drobnych ulepszeń. Przed udostępnieniem aktualizacji przeprowadzono wewnętrzne testy, które nie ujawniły żadnych (!) nieprawidłowości.
Chwilę po wdrożeniu aktualizacji zaczęły jednak spływać pierwsze zgłoszenia o problemach. Użytkownicy w Azji i Australii, gdzie był już piątkowy poranek, zaczęli raportować, że ich komputery z systemem Windows nieoczekiwanie się restartują i wyświetlają "niebieski ekran śmierci". Pierwsze problemy zauważono na lotniskach w Sydney i Hong Kongu. Mijały kolejne godziny, a problem zaczął być widoczny w coraz większej liczbie miejsc na świecie, wraz z kolejnymi strefami czasowymi wchodzącymi w nowy dzień roboczy. Nie trzeba było czekać zbyt długo, zanim zgłoszenia o awariach zaczęły napływać także z Europy i ze wschodniego wybrzeża Stanów Zjednoczonych.
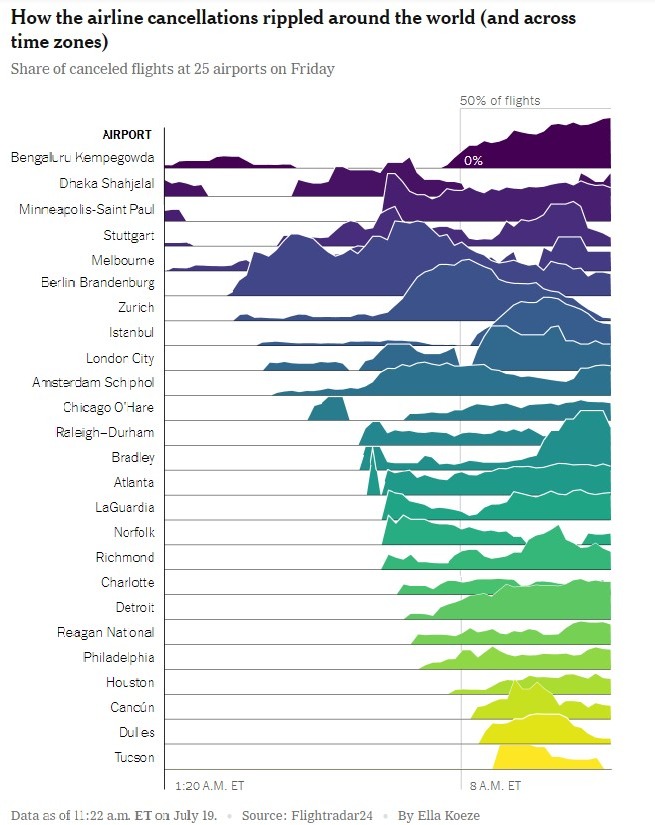
Kilka godzin po wysłaniu aktualizacji problem przybrał już globalne rozmiary. Linie lotnicze na całym świecie zaczęły uziemiać swoje samoloty, szpitale zgłaszały problemy z systemami, a firmy w różnych sektorach gospodarki doświadczały poważnych zakłóceń w działaniu.
CrowdStrike w końcu zidentyfikowało źródło problemu, ale ze względu na charakter awarii, natychmiastowe rozwiązanie nie było możliwe. Firma rozpoczęła prace nad poprawką, jednocześnie starając się powstrzymać dalsze rozprzestrzenianie się wadliwej aktualizacji.
Skala i zasięg awarii
Awaria dotknęła szeroki zakres sektorów, demonstrując przy tym, jak powszechne jest wykorzystanie oprogramowania CrowdStrike. Co najmniej pięć dużych linii lotniczych w USA oraz wiele międzynarodowych przewoźników musiało odwołać loty, a porty lotnicze na całym świecie zgłaszały masowe opóźnienia. Szpitale w wielu krajach były zmuszone odwołać planowane operacje i ograniczyć usługi ze względu na problemy z systemami komputerowymi. Szczególnie dotknięta została sieć Providence Health w USA, z 52 szpitalami w siedmiu stanach, a systemy 911 w wielu stanach USA przestały działać, co bezpośrednio zagrażało bezpieczeństwu publicznemu.
Duże banki, takie jak TD Bank, zgłaszały problemy z dostępem klientów do kont online. Awaria dotknęła również firmy kurierskie, w tym UPS i FedEx, które raportowały zakłócenia w swoich operacjach. Problem dotknął także wiele systemów sądowych na poziomie stanowym i miejskim, które zostały zamknięte na cały dzień, podobnie jak niektóre sieci handlowe, które musiały zamknąć swoje sklepy ze względu na problemy z systemami kasowymi.
Dokładna liczba dotkniętych użytkowników i urządzeń nie została oficjalnie podana, ale bazując na skali działalności CrowdStrike, można oszacować, że awaria miała wpływ na co najmniej kilka milionów komputerów z systemem Windows i setki milionów osób na całym świecie, które doświadczyły zakłóceń w usługach lotniczych, bankowych, medycznych i innych.
Reakcja CrowdStrike
George Kurtz, dyrektor generalny CrowdStrike, wydał oficjalne oświadczenie, w którym przyznał się do błędu i wziął pełną odpowiedzialność za incydent. Wyraził także głębokie ubolewanie z powodu wpływu awarii na klientów, podróżnych i wszystkie dotknięte osoby i zapewnił, że firma intensywnie pracuje nad rozwiązaniem problemu.
CrowdStrike istotnie podjęło adekwatne kroki naprawcze, jednak nie podało dokładnego czasu, w jakim wszystkie systemy zostaną przywrócone do pełnej funkcjonalności. Kurtz ostrzegł, że "może minąć trochę czasu, zanim systemy technologiczne wrócą do normalności". Mimo wszystko firma zobowiązała się do regularnego informowania o postępach w przywracaniu systemów i zapewniła, że będzie pracować nieustannie, aż wszystkie problemy zostaną rozwiązane.
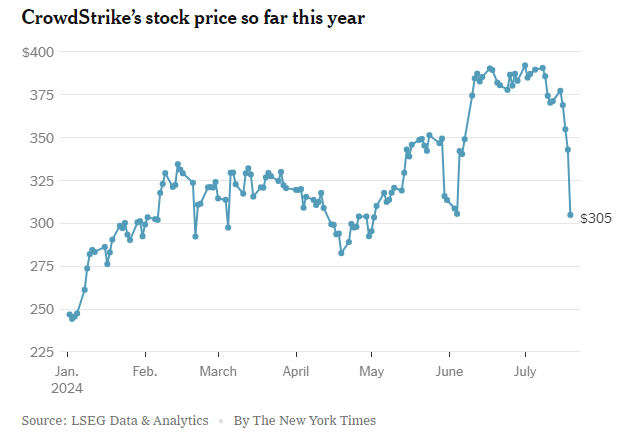
Na spowodowaną przez CrowdStrike awarię bardzo szybko zareagowała giełda, w efekcie czego jej akcje spadły o 11% w dniu awarii. To świadczy o poważnym wpływie incydentu na zaufanie inwestorów.
 Incydent z CrowdStrike boleśnie uwidocznił, jak krucha jest nasza globalna infrastruktura cyfrowa. W czasach, gdy niemal każdy element naszego życia - od transportu po opiekę zdrowotną - jest uzależniony od technologii, pojedynczy błąd w oprogramowaniu może wywołać efekt domina o nieprzewidywalnych konsekwencjach.
Incydent z CrowdStrike boleśnie uwidocznił, jak krucha jest nasza globalna infrastruktura cyfrowa. W czasach, gdy niemal każdy element naszego życia - od transportu po opiekę zdrowotną - jest uzależniony od technologii, pojedynczy błąd w oprogramowaniu może wywołać efekt domina o nieprzewidywalnych konsekwencjach.
Ta sytuacja zmusza nas do głębokiej refleksji nad fundamentami, na których zbudowana jest nasza cyfrowa cywilizacja. Okazuje się, że w pogoni za efektywnością i innowacją, mogliśmy nieświadomie stworzyć system, który jest zbyt wrażliwy na pojedyncze punkty awarii.
Potrzeba większej odporności systemów staje się teraz jeszcze bardziej oczywista i nie chodzi tu tylko o techniczne usprawnienia, ale o całościowe przemyślenie naszego podejścia do projektowania infrastruktury cyfrowej. Musimy dążyć do stworzenia systemów, które są nie tylko wydajne, ale przede wszystkim odporne na awarie i zdolne do szybkiej regeneracji. To wyzwanie, które wymaga współpracy na wielu poziomach - od firm technologicznych, poprzez rządy, aż po użytkowników końcowych. Potrzebujemy nowych standardów, lepszych praktyk i zwiększonej świadomości ryzyka.
Incydent z CrowdStrike powinien być dla nas wszystkich sygnałem alarmowym. Pokazuje on, że w erze cyfrowej bezpieczeństwo i stabilność nie są luksusem, ale koniecznością. Musimy zacząć inwestować w budowę bardziej odpornej infrastruktury cyfrowej, która będzie w stanie wytrzymać nie tylko celowe ataki, ale również niezamierzone błędy.
Ostatecznie, nasza zdolność do tworzenia odpornych systemów cyfrowych będzie bardzo ważnym czynnikiem determinującym stabilność i bezpieczeństwo naszego społeczeństwa w przyszłości. To nie jest już kwestia tylko technologii - to kwestia naszego zbiorowego bezpieczeństwa i dobrobytu w coraz bardziej cyfrowym świecie.
Komentarz Radka Smilgina
Do globalnej awarii systemów informatycznych nazywanej „największą w historii IT” przyczynił się 1 defekt. Słownie JEDEN.
Wbrew wielu opiniom nie był to defekt bezpieczeństwa, choć dotyczył narzędzia zabezpieczającego. Był to najzwyklejszy defekt funkcjonalny, który nie został znaleziony w najzwyklejszym procesie testowania. Aby go odkryć przed wejściem na produkcję wystarczył JEDEN tester z JEDNYM dobrym testem.
JEDNA firma (CrowdStrike) ze swoim zabugowanym oprogramowaniem i przez zbyt duże zaufanie, którym obdarzył ją Microsoft, była w stanie sparaliżować połowę świata. Gdyby tylko jedni i drudzy więcej testowali...
Najlepsze jest to, że dziś zostaną znalezione tysiące defektów. Ich wyjście na produkcję miałoby, może nie tak duże, ale na pewno katastrofalne skutki. Przez nie jakieś systemy przestałyby działać, a czyjeś życie byłoby zagrożone.
Gdzieś tam armia bezimiennych testerów, jak co dzień, znów uratuje świat.