Krzysztof Kołodziejczyk
Krzysztof Kołodziejczyk


Sam temat generowania elementów wizualnych przez AI w ostatnim czasie stał się nad wyraz kontrowersyjnym tematem. Oczywiście nie tylko elementy wizualne są poddawane pod dyskusję, natomiast są one czynnikiem zapalnym, który rzutuje na inne formy generowanego przez AI kontentu. Persony z różnych grup artystycznych czy indywidualni twórcy stali się jedną ze stron w nierównej walce ze sztuczną inteligencją.
Niemniej jednak generowanie treści audiowizualnych jest to jedna z form treści, którą możemy posłużyć się do osiągnięcia własnych celów. Spróbujmy posłużyć się w pierwszym przykładzie popularnym tematem blogów zawierających elementy „obrazkowe”. Wygenerujmy obraz z przykładową treścią, którą możemy w takiej sytuacji wykorzystać.
Przykład zapytania:
 Przykładowy fragment odpowiedzi:
Przykładowy fragment odpowiedzi:
 Oczywiście generowanie prostych obrazów jest tylko namiastką tego, co można stworzyć za pomocą AI. Same obrazy mogą być tworzone w różnych stylach i wariacjach.
Oczywiście generowanie prostych obrazów jest tylko namiastką tego, co można stworzyć za pomocą AI. Same obrazy mogą być tworzone w różnych stylach i wariacjach.
W celu wykorzystania pełnego potencjału generowania obrazów, możemy użyć dedykowanego narzędzia DALLE 2, czyli systemu do przetwarzania tekstu na obraz. Po wskazaniu opisu tekstowego, system spróbuje wygenerować od podstaw nowy obraz, który do niego pasuje. Posiada również dodatkowe możliwości, takie jak:
- inpainting - edytuj obraz za pomocą języka
- wariacje - generowanie nowych obrazów, które mają tę samą istotę, co dany obraz referencyjny, ale różnią się sposobem ułożenia szczegółów

- różnice tekstowe: przekształć dowolny aspekt obrazu za pomocą języka

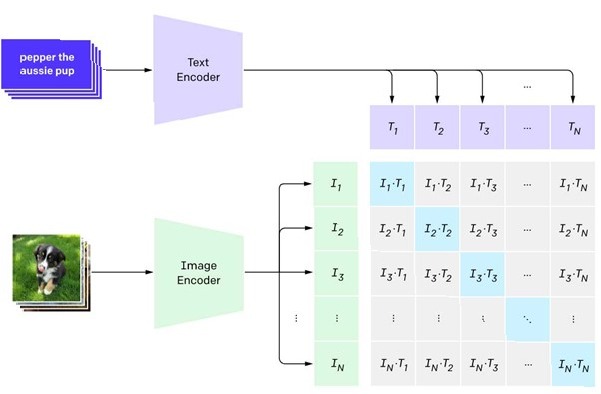
System leżący u podstaw DALL·E 2, który nazywamy unCLIP, opiera się na dwóch kluczowych technologiach: CLIP i dyfuzji. Jak stwierdzono na blogu, CLIP to model, który „efektywnie uczy się koncepcji wizualnych pod nadzorem języka naturalnego”. Dyfuzja to technika trenowania generatywnego modelu obrazów poprzez uczenie się cofania kroków ustalonego procesu korupcji. Poniżej krótko opiszemy obie te technologie.
Ilustracja celu treningu kontrastowego dla CLIP:
 Ilustracja procesu użytego do wygenerowania nowego obrazu z modelem dyfuzyjnym, stworzonym przez Alexa Nichola:
Ilustracja procesu użytego do wygenerowania nowego obrazu z modelem dyfuzyjnym, stworzonym przez Alexa Nichola:

Model dyfuzji jest szkolony w zakresie cofania kroków ustalonego procesu korupcji. Każdy etap procesu korupcji dodaje niewielką ilość hałasu. W szczególności szum gaussowski do obrazu, co powoduje usunięcie niektórych zawartych w nim informacji.
DALL·E 2 generuje obrazy w procesie dwuetapowym, najpierw generując „sedno” obrazu, a następnie wypełniając pozostałe szczegóły w celu uzyskania realistycznego obrazu. W pierwszym etapie model, który nazywamy priorem, generuje osadzanie obrazu CLIP (mające na celu opisanie „sedna” obrazu) z zadanego podpisu. Ktoś mógłby zapytać, dlaczego ten wcześniejszy model jest konieczny? Dzieje się tak, ponieważ koder tekstu CLIP jest szkolony w celu dopasowania do wyjścia kodera obrazu. Dlaczego nie użyć wyjścia kodera tekstu jako „sedna” obrazu? Odpowiedź jest prosta: z danym podpisem może być zgodna nieskończona liczba obrazów, więc wyjścia dwóch koderów nie będą się idealnie pokrywać. W związku z tym potrzebny jest osobny wcześniejszy model, aby „przetłumaczyć” osadzony tekst na osadzony obraz, który mógłby go wiarygodnie dopasować. W drugim etapie model dyfuzji, który nazywamy unCLIP, generuje sam obraz z tego osadzania. Na każdym etapie uczenia unCLIP otrzymuje zarówno uszkodzoną wersję obrazu, który ma rekonstruować, jak i osadzony obraz CLIP czystego obrazu. Ten model nazywa się unCLIP, ponieważ skutecznie odwraca mapowanie obrazu CLIP wyuczone przez koder. Ponieważ unCLIP jest wyszkolony w zakresie „wypełniania szczegółów” niezbędnych do uzyskania realistycznego obrazu z osadzania, nauczy się modelować wszystkie informacje, które CLIP uzna za nieistotne dla celu szkolenia, a zatem w rezultacie je odrzuci.
Rysunek 4: animacja różnic tekstowych użytych do przekształcenia wiktoriańskiego domu w nowoczesny. Transformację określają napisy „dom wiktoriański”, który opisuje architekturę domu, oraz „dom nowoczesny”, który opisuje, w jaki sposób należy zmienić architekturę domu.
Poprzedni wpis, w którym przestawiliśmy zastosowanie ChatGPT do generowania tekstu, znajdziecie tutaj.