Marcin Krężel
Marcin Krężel


Należy szczególnie zwrócić uwagę na fakt, iż oprogramowanie z reguły powstaje w zespołach co oznacza, że aplikując dobre praktyki oraz technologiczne udogodnienia we wczesnym etapie projektowania produktu (np. frameworku testów automatycznych) będziemy mieli większą kontrolę nad utrzymaniem, rozwojem naszego kodu oraz zwiększy to tzw. reużywalność wybranych modułów przez innych członków zespołu.
Reprezentacja pliku konfiguracyjnego
Jednym z wyzwań obok wyboru odpowiedniej technologii i wzorca projektowego przy budowie frameworku testów automatycznych jest standaryzacja sposobu zarządzania modelami danych w kodzie. Języki programowania takie jak Python dają nam do dyspozycji wbudowane typy danych do przechowywania i obróbki prostych oraz złożonych form naszych danych. Dobór odpowiedniego typu dla wybranego problemu programistycznego jest bardzo ważnym krokiem przy tworzeniu aplikacji.
Testy automatyczne w kodzie
Przeanalizujmy poniższy przykład. Budujemy framework testów automatycznych przy użyciu Pythona, biblioteki pytest oraz Selenium, do którego dokładamy plik konfiguracyjny ładujący wybrane dane przy starcie naszych testów. Nasz plik config.json zawiera podstawowe zmienne takie jak rodzaj przeglądarki, w której odpalimy testy, domyślna wartość waita, oraz wartość typu Boolean wskazującą na to, czy przeglądarka powinna uruchomić się w trybie headless.
json
{
"browser": "chrome",
"implicit_wait": 5,
"headless": false
}
Do inicjacji naszej konfiguracji wykorzystamy mechanizm testowej fikstury, z biblioteki pytest. Fikstury to specjalne rodzaje funkcji, które wykonują określone instrukcje przed bądź po testach. Stwórzmy plik conftest.py, w którym umieścimy nasze fikstury. Z racji, że plik konfiguracyjny jest plikiem json, pierwsza myśl, jaka może przyjść nam do głowy, to załadowanie naszej konfiguracji do wbudowanego typu danych Pythona jakim jest słownik.
python
import pytest
import json
from pathlib import Path
@pytest.fixture
def config() -> dict:
path = Path(__file__).parent / "../data/config.json"
with open(path) as file:
return json.load(file)
Inicjacja danych konfiguracyjnych w ten sposób nie mówi nam nic o modelu danych jaki jest zawarty w pliku json. Żeby zrozumieć, jak wygląda jego struktura, będziemy musieli podglądać jego zawartość. Operowanie wybranymi elementami w konfiguracji sprowadza się do pracy na pythonowych słownikach, to znaczy, że chcąc wyciągnąć wartość zdefiniowanego w configu waita musimy znać dokładną wartość klucza pod którą ta dana jest przechowywana: config['implicit_wait']. Podanie błędnej wartości klucza, co w cale nie będzie takie trudne, w końcu to string, spowoduje przerwanie programu przez zgłoszenie pythonowego wyjątku:
python
def test_main(config):
data = config["wrong key value"]
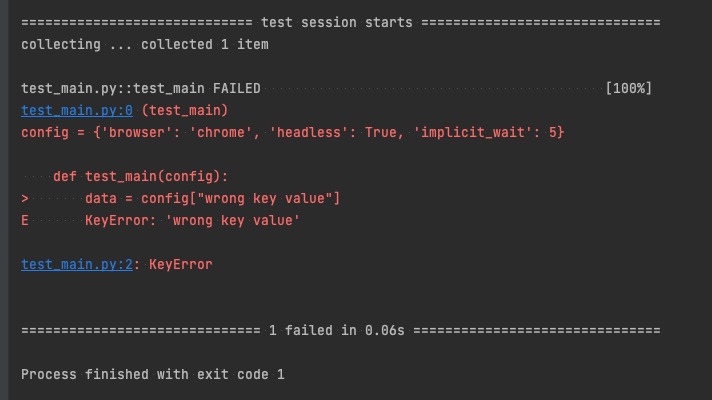 (Rys. 1) - Wyjątek KeyError po próbie odwołania się do nieistniejącego klucza.
(Rys. 1) - Wyjątek KeyError po próbie odwołania się do nieistniejącego klucza.
Przeanalizujmy użycie mechanizmu konfiguracji w fiksturze inicjującej obiekt drivera przeglądarki Chrome od selenium.
python
import pytest
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
@pytest.fixture
def init_driver(config):
driver = None
if config["browser"] == "chrome":
driver_exec_path = ChromeDriverManager().install()
s = Service(driver_exec_path)
options = Options()
driver = webdriver.Chrome(service=s)
if config["headless"]:
options.add_argument("--headless")
return driver
W powyższym przykładzie odwołujemy się do danych konfiguracyjnych jak do słownika. Na ten moment zaawansowania naszego frameworku jest to ok, ale co jeśli będziemy chcieli umożliwić uruchamianie się naszych testów na kilku przeglądarkach, albo gdybyśmy chcieli dodać fikstury, które będą walidować zawarte w configu dane takie jak poprawna nazwa przeglądarki. Nasze mechanizmy fikstur będą się rozwijać, a my wciąż nie będziemy mieli żadnej reprezentacji naszej konfiguracji w kodzie. Ewidentnie potrzebujemy tutaj jakieś struktury pośredniej, która będzie nam spajać rzeczywisty plik z używaniem danych konfiguracyjnych w kodzie testów. Na początku artykułu wspomniano o wartości, jakie może wnieść korzystanie z technologicznych udogodnień specyficznych dla danego języka dla naszego projektu. Dla Pythona jednym z takich udogodnień są dataclassy.
Dataclassy w Pythonie
W klasycznym pojęciu programowania obiektowego klasa to: "definicja obiektu przechowująca jego stan oraz zachowania". Dataclassę można natomiast zdefiniować jako klasę, która została zaprojektowana do reprezentowania obiektów zawierających stan bez skomplikowanej logiki. Przykładem użycia tej struktury będzie reprezentacja takich obiektów jak punkt lub wektor, czyli takich, które w większej mierze wyrażamy przez ich stan a nie przez ich zachowania. Technicznie rzecz biorąc dataclassy są tzw. nakładką na zwykłe klasy pythonowe, a ich używanie ma jedynie ułatwiać pracę developera w tworzeniu obiektów zorientowanych na dane. Przeanalizujmy poniższy przykład.
python
class Point:
def __init__(self, x: int, y: int):
self.x = x
self.y = y
p = Point(10, 10)
Zdefiniowaliśmy klasę Point, która reprezentuje punkt w dwuwymiarowym układzie współrzędnym. Aby stworzyć obiekt klasy musimy napisać metodę __init__, która inicjuje obiekt klasy Point poprzez tworzenie jej atrybutów.
Sprawdźmy jak dla takiego samego przykładu użyć dataclassy.
python
from dataclasses import dataclass
@dataclass
class Point:
x: int
y: int
p = Point(10, 10)
Stworzenie dataclassy sprowadza się do wykorzystania dekoratora zaimportowanego z paczki dataclasses. Dodatkowo nie musimy tworzyć metody __init__, wystarczy przekazać atrybuty klasy oraz podać ich typy. Oprócz rzucających się w oczy ułatwień w definiowaniu klasy, dataclassy zawierają również wiele pomocnych mechanizmów takich jak m.in. :
- reprezentacja obiektu w postaci stringa (w zwykłych klasach dla analogicznego zachowania wymagana jest implementacja metod specjalnych
__str__i/lub__repr__) - porównywanie kilku obiektów pochodzących z tej samej klasy
- metodę specjalną
__post_init__, której można użyć jako walidator zainicjowanych atrybutów klasy - możliwość zdefiniowania klasy i wszystkich ich argumentów jak niezmienne (ang. immutable), ustawiając pole w funkcji dekorującej naszą klasę:
frozen=True - definiowanie defaultowych wartości atrybutów (dostępne również w normalnych klasach).
Zmodyfikujmy nieco klasę Point, by zobrazować wymienione powyżej przykłady:
python
from dataclasses import dataclass
@dataclass(frozen=True)
class Point:
x: int
y: int = 10
def __post_init__(self):
if type(self.x) is not int:
return ValueError(f"Wrong type of the x the attribute.")
p = Point(10, 10)
p1 = Point(10)
print(f"String representation of p object defined in dataclass: {p}")
print(f"String representation of p1 object defined in dataclass: {p1}")
if p == p1:
print("The compared objects are equal")
p.x = 999
Wykonanie powyższego kodu w terminalu da nam wynik:
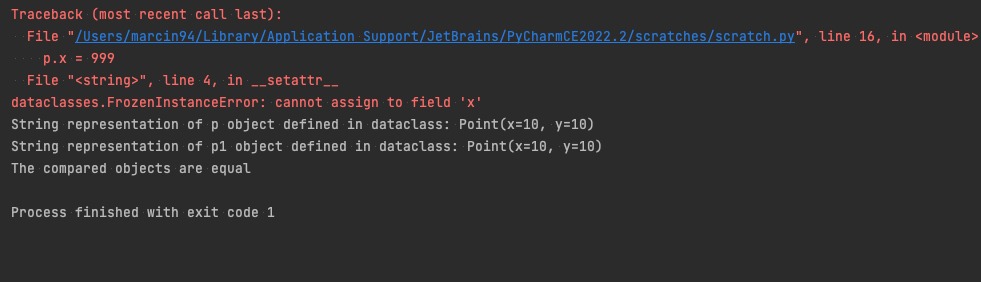 (Rys. 1.2) - Przykłady operacji na obiektach definiowanych jako dataclassy.
(Rys. 1.2) - Przykłady operacji na obiektach definiowanych jako dataclassy.
Tak, jak zakładaliśmy, opcja automatycznej reprezentacji obiektu w formie stringa oraz porównywania dwóch obiektów o tych samych atrybutach działa jak powinno. Próba zmiany wartości atrybutu klasy x przerwała nam program zwracając błąd, zatem parametr dekoratora @dataclass(frozen=True) również zadziałał wg naszych założeń. Walidacja zawarta w metodzie __post_init__ nie zwróciła błędu, a wartość domyślna atrybutu Point.x została poprawnie wykorzystana przy inicjacji obiektu p1.
Wykorzystanie dataclass w fiksturze ładującą dane konfiguracyjne
To tyle z teorii, ale jak użyć tego w praktyce? Zdefiniujmy klasę reprezentująca plik konfiguracyjny w naszym pliku zawierającym fikstury testowe conftest.py. Na tym etapie zaawansowania frameworku jest to jak najbardziej poprawne jednak w przypadku, gdy nasz plik z fiksturami będzie rósł, dobrym pomysłem byłoby wydzielenie tej klasy do pythonowej paczki o nazwie models/. Do umiejętnego zdefiniowania modelu pliku config wykorzystamy wszystkie informacje o dataclassach jakie przedstawiono w ramach niniejszego artykułu
python
import json
from dataclasses import dataclass
from pathlib import Path
import pytest
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
@dataclass
class Config(frozen=True):
browser: str
headless: bool
implicit_wait: int = 10
def __post_init__(self):
if self.browser not in ["chrome", "firefox", "edge"]:
ValueError("Given browser is not supported.")
@pytest.fixture
def config() -> Config:
path = Path(__file__).parent / "../data/config.json"
with open(path) as file:
config = json.load(file)
return Config(**config)
@pytest.fixture
def init_driver(config: Config):
driver = None
if config.browser == "chrome":
driver_exec_path = ChromeDriverManager().install()
s = Service(driver_exec_path)
options = Options()
driver = webdriver.Chrome(service=s, options=options)
if config.headless:
options.add_argument("--headless")
return driver
Powyższy kod pokazuje praktyczne użycie dataclassy w module test/conftest.py zawierającym fikstury testowe odpowiadające za uruchamianie naszych testów. Przeanalizujmy zmiany w naszym kodzie.
Wprowadzenie modelu w postaci klasy wprowadza konkretną reprezentację tego, jak wygląda i czego możemy się spodziewać po pliku config. Wykorzystanie specjalnych zdolności dataclass pozwala:
- wyeliminować ryzyko przypadkowej niechcianej zmiany wartości jakiegoś pola konfiguracji w kodzie poprzez zdefiniowania dataclassy z jej atrybutami jako niezmiennymi (eng. immutable)
- zdefiniować defaultową wartość pola
implicit_wait: int = 10w przypadku, gdy z jakiś powodów zabraknie tego pola w pliku konfiguracyjnym json (np. powstanie nowa błędna wersja tego pliku) model wykorzysta jego wartość domyślną - poddać walidacji pole
browserpod kątem możliwości obsługi danego typu przeglądarki zawartej w pliku config.
Oprócz zmian w inicjacji, walidacji i konfiguracji, dużym usprawnieniem jest sam sposób używania tego modelu. W przeciwieństwie do poprzedniej wersji fikstury init_driver, w której odwoływanie się do konkretnych pól obiektu konfiguracyjnego (przechowywanego w słowniku) wymagało od nas podania wartości kluczy w postaci stringa.
Przypominając: config['browser']. Mając ten sam model danych w formie dataclassy, odnosimy się do poszczególnych pól jak do zwykłych atrybutów obiektu. Każdy nowowczesny IDE (np. PyCharm, Visual Studio Code), będzie nam ułatwiał pracę, podpowiadając nazwy dostępnych atrybutów dla obiektu wybranego typu, czego nie mogliśmy doświadczyć przy pracy na pythonowym słowniku.
Podsumowanie
Umiejętne korzystanie z udogodnień, jakie oferuje nam język programowania w jakim pracujemy, jest równie ważne jak znajomość dobrych praktyk i wzorców projektowych. Dataclassy to bardzo potężny mechanizm pozwalający w szybki i intuicyjny sposób zdefiniować model jakichś danych. Ich używanie w znacznym stopniu może poprawić czytelność kodu w naszym frameworku oraz ułatwić korzystanie z modeli danych zdefiniowanych w ten sposób.
Oprócz funkcjonalności wymienionych w artykule, biblioteka dataclasses zawiera jeszcze dużo ciekawych zastosowań. Więcej o dataclassach można przeczytać pod tym linkiem.
Kod źródłowy zawierający prezentowany framework: https://github.com/markre94/Dataclasses---Selenium-pytest-example