Sławomir Radzymiński
Sławomir Radzymiński


Minęły już czasy kiedy jedynym godnym uwagi narzędziem do testów wydajnościowych był JMeter. Z biegiem czasu utrzymywanie jednego gigantycznego pliku xml będącego definicją wszystkich scenariuszy okazało się nieskalowalne i najzwyczajniej w świecie trudne. Utrzymywanie zależności pomiędzy poszczególnymi zapytaniami HTTP jest o wiele prostsze w kodzie, który możemy tworzyć według potrzeb i standardów zespołowych. Ponadto deweloperzy i inni członkowie zespołu o wiele chętniej zaglądają i modyfikują kod testów. Nie mamy tutaj bariery wejścia i konieczności nauki obsługi interfejsu użytkownika JMetera.
Obecnie mamy spory wybór narzędzi do testów wydajnościowych. Wśród darmowych dominuje Locust (gdzie testy piszemy w Pythonie), Gatling (Scala, Kotlin lub Java) i K6 (JavaScript/TypeScript). Chcąc wykonać szybki i prosty test najlepiej sięgnąć po Vegetę, która wymaga jedynie dostępu do konsoli.
Dzisiaj chciałbym zapoczątkować serię artykułów o testach wydajnościowych przedstawiając narzędzie, które bardzo szybko zyskuje na popularności, czyli K6. K6 używany jest z powodzeniem między innymi przez Gitlab i jest w pełni darmowy. Mamy również możliwość wygenerowania obciążenia ze środowiska chmurowego, ale to oczywiście jest już płatne.
K6 umożliwia nam uruchomienie skryptów napisanych w dość starej wersji języka JavaScript (ES5.1) dlatego jako punktu startowego rekomenduję użycie TypeScriptowego szablonu dostarczonego przez Grafanę (firmę opiekującą się K6), dostępnego tutaj. Szablon ten umożliwia nam wykorzystanie wszystkich najnowszych funkcjonalności TypeScripta i NodeJS. Ponadto, dzięki npm mamy możliwość łatwego zarządzania zależnościami. Aby uruchomić test musimy transpilować kod napisany w TypeScripcie do starszej wersji JSa (ES5.1) za pomocą Babela i zbudować jeden, uruchamialny przez K6 plik z testem za pomocą webpacka. Wszystkie te funkcjonalności mamy już skonfigurowane w powyższym szablonie więc możemy się skupić tylko i wyłącznie na pisaniu testów.
W pierwszym artykule skupimy się na podstawach, które mam nadzieję umożliwią czytelnikom budowanie bardziej złożonych scenariuszy. Zacznijmy od zapytania HTTP.
<script src="https://gist.github.com/slawekradzyminski/081827f81f384671b684059df7d26b85.js"></script>
W domyślnej funkcji definiujemy nasz scenariusz testowy. Zaczynamy od przypisania odpowiedzi na zapytanie GET do zmiennej. Następnie mamy funkcję check(), która umożliwia nam wykonanie sprawdzenia na poziomie funkcjonalnym. W naszym przypadku interesuje nas konkretny status odpowiedzi (200). Sprawdzenia funkcjonalne w testach wydajnościowych powinny być bardzo proste. Nie chcemy weryfikować konkretnych wartości pól, ale chcemy mieć pewność, że nasz ruch odzwierciedla rzeczywistość. Mierzenie czasów odpowiedzi dla błędnych zapytań byłoby bezwartościowe. Test kończy się sekundowym czekaniem. Czekanie w testach wydajnościowych nie jest czymś złym. Chcąc zasymulować użytkownika klikającego po naszej stronie staramy się wprowadzać realistyczne przerwy pomiędzy poszczególnymi akcjami użytkownika.
Zmienna options pozwala skonfigurować k6 i test na nasze potrzeby. Wśród najpopularniejszych opcji jest ustawianie ilości symultanicznych użytkowników (vus), iteracji (iterations), oczekiwanych czasów odpowiedzi dla poszczególnych percentyli (thresholds: { http_req_duration: ['avg<100', 'p(95)<200')] }), oraz włączanie trybu debug, który loguje całe zapytania wraz z odpowiedziami (httpDebug: ‘full’). Pełną listę znajdziemy w świetnie utrzymanej dokumentacji.
No dobrze, to jak w takim razie uruchomić nasz test? Oto co musimy zrobić:
- Instalujemy k6
- Instalujemy yarna
- Instalujemy zależności naszego projektu za pomocą komendy yarn install
- Budujemy wykonywany skrypt k6 za pomocą komendy yarn webpack
- Uruchamiamy wynikowy skrypt za pomocą komendy k6 run dist/get-200-status-test.js
Naszym oczom powinien ukazać się raport z testu.
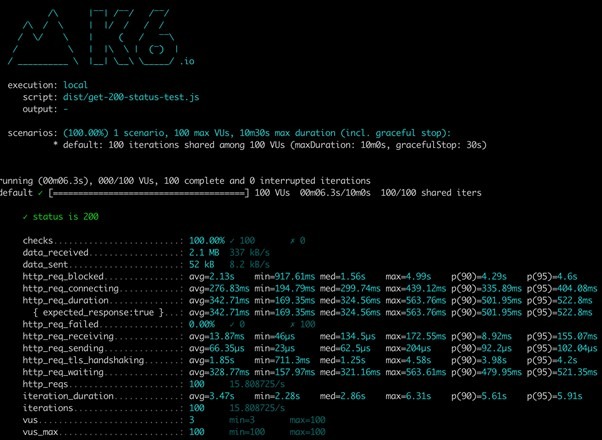
Zwracam uwagę na wspomniane wcześniej checki. Raport mówi nam, że w przypadku wszystkich zapytań (http_reqs = 100) uzyskaliśmy pożądany kod odpowiedzi - 200. Mamy również dokładne informacji na temat czasów odpowiedzi (średnia, minimalna, mediana, maksymalna, percentyl 90 i percentyl 95).
Szablon k6 z TypeScriptem umożliwia nam pisanie testów, które są bardzo proste do zrozumienia na pierwszy rzut oka, np. w tym przypadku:
<script src="https://gist.github.com/slawekradzyminski/6f78ae853120ce60d11b63dca9f208f8.js"></script>
Już na pierwszy rzut oka widać dokładnie jak wygląda nasz scenariusz do testu wydajnościowego:
- generujemy użytkownika
- rejestrujemy użytkownika przy pomocy wygenerowanych danych
- logujemy użytkownika i zwracamy jego token
- token użytkownika używamy do kolejnych zapytań, w tym wypadku do pobrania listy użytkowników
Przyjrzyjmy się zatem rejestracji, jak wygląda budowanie zapytania HTTP?
<script src="https://gist.github.com/slawekradzyminski/8f049c260d3321a69f1277c34718dec0.js"></script>
Kod jest właściwie bardzo prosty. Na podstawie obiektu typu User budujemy ciało zapytania za pomocą JSON.stringify(body). Następnie dodajemy weryfikację, że rejestracja się udała, tj. zwróciła kod odpowiedzi 201.
Czytelników zachęcam do własnoręcznego sprawdzenia czy kod jest poprawny. Wystarczy:
- uruchomić środowisko testowe dostępne tutaj,
- uruchomić testy dostępne tutaj.
Jak Wam się podoba artykuł? Czy chcielibyście poznać K6 w sposób bardzo szczegółowy? A może chcecie zobaczyć jak testować wydajnościowo przy pomocy Gatlinga? Może potrzeba więcej teorii? Dajcie znać w komentarzach. :)