Marek Żukowicz
Marek Żukowicz


Dane testowe to wartości, które wprowadza się do testowanego systemu jako dane wejściowe dla pewnej funkcjonalności w celu weryfikacji lub walidacji poprawności tej funkcjonalności. Dane wejściowe są nierozerwalnie związane z przypadkiem testowym, o czym piszą Anna Piaskowy oraz Radosław Smilgin w książce "Dane Testowe. Teoria i praktyka". Są to informacje o tym, jakie wartości należy podstawić do funkcji realizującej wymaganie w systemie. Istnieje wiele technik, które pozwalają ułatwić wybór danych tak, aby były one zgodne z danymi rzeczywistymi, czyli takimi, które będę wprowadzane do aplikacji przez potencjalnych użytkowników.
1. Wprowadzenie
Dane testowe powinny wg autorów pozycji [19], [6] odznaczać się takimi cechami jak:
- wydajność (może być rozumiana jako czas wykonania testu),
- zależność od systemu (jakość zależy od aspektów technologicznych),
- zupełność (stopień, w jakim te dane mają wartość dla wszystkich atrybutów w systemie),
- wiarygodność,
- spójność (np. niesprzeczność pomiędzy danymi testowymi),
- dostępność (stopień, w jakim te dane mogą być uzyskane przez użytkownika),
- precyzyjność (dotyczy testów na liczbach, w aplikacjach które wymagają dużej dokładności np. przeliczanie miar czy jednostek).
Na przełomie ostatnich 20 lat wraz z rozwojem strategii ewolucyjnych pojawiły się pomysły zastosowanie takich strategii w procesie generowania danych testowych. Początki takich prac sięgają drugiej połowy lat 90 np. pozycja [10]. Strategie ewolucyjne dzielą się na programowanie ewolucyjne, algorytmy genetyczne oraz algorytmy ewolucyjne. Różnice między algorytmami genetycznymi oraz algorytmami ewolucyjnymi nie są wielkie. Zdarza się że te nazwy są stosowane zamiennie w publikacjach. Celem napisania niniejszej pracy jest ogólny przegląd zastosowania strategii ewolucyjnych w procesie generowania danych testowych oraz wskazanie wartości jakie mogą przynieść strategie ewolucyjne w procesie testowania aplikacji.
2. Jak działają strategie ewolucyjne?
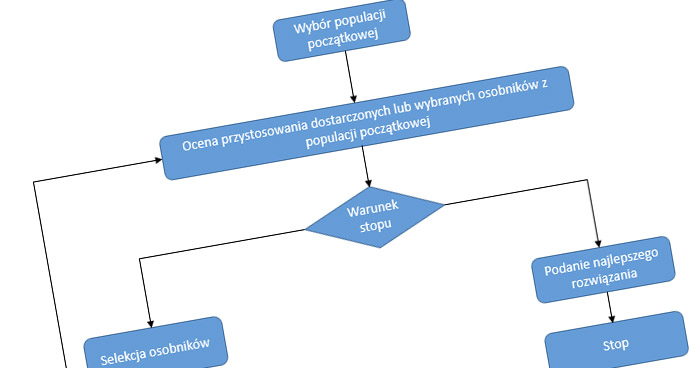
Schemat działania strategii ewolucyjnej przedstawia obrazek:

Rys. 1: Schemat działanie algorytmu ewolucyjnego – opracowanie własne.
Ogólne działanie strategii ewolucyjnej można opisać w następujący sposób:
a) Algorytm ewolucyjny rozpoczyna proces przeszukiwania, czyli znalezienia optymalnego rozwiązania od utworzenia bądź wykorzystania dostarczonej populacji możliwych rozwiązań, które można potraktować analogicznie jak argumenty pewnej funkcji wielu zmiennych. Słowo populacja może oznaczać po prostu zbiór liczb, zbiór wektorów, inne obiekty, które mogą być poddawane ocenie pod względem jakości rozwiązania.
b) W każdym ewolucyjnym kroku (iteracji algorytmu), chromosomy (inna nazwa osobników z danej populacji) są ocenianie zgodnie z pewnym z góry przyjętym kryterium jakości nazywanym przystosowaniem (funkcją przystosowania może być na przykład funkcja celu, może to być funkcja , która jest sumą kilku funkcji mnożonych przez wagi), a następnie przeprowadzana jest selekcja w celu eliminacji osobników ocenionych jako najgorsze (odrzucanie najgorszych albo wybór najlepszych).
c) Osobniki wykazujące wysokie przystosowanie podlegają selekcji np. metoda ruletki, następnie mutacji oraz rekombinacji przeprowadzanej przy pomocy operatora krzyżowania w celu wygenerowania nowego pokolenia. Sama selekcja nie wprowadza żadnego nowego osobnika do populacji, tj. nie znajduje nowych punktów w przestrzeni poszukiwań, natomiast takie punkty wprowadzane są przez krzyżowanie i mutację. Mutacja zapobiega zbieżności do lokalnego optimum.
d) W wyniku działania operatora krzyżowania i mutacji tworzone są nowe rozwiązania, z których następnie budowana jest populacja następnej generacji. Warunkiem zakończenia algorytmu może być na przykład pewna określona liczba generacji albo osiągnięcie zadawalającego poziomu przystosowania.
3. Co piszą naukowcy na temat generowania danych testowych za pomocą metod ewolucyjnych?
W tym rozdziale przedstawiony zostanie ogólny przegląd strategii generowania danych testowych za pomocą metod opartych o strategie ewolucyjne. Propozycje autorów artykułów naukowych są bardzo różne. Często pojawiają się w publikacjach grafy znane z matematyki, ponieważ to bardzo dobre obiekty, za pomocą których można stworzyć model przepływu danych lub model zależności danych. Strategie ewolucyjne działają również na zbiorach przypadków testowych, przy testach jednostkowych, przy testowaniu strukturalnym. Osoby piszące publikacje wykorzystują grafy w taki sposób, żeby za ich pomocą zaimplementować algorytm ewolucyjny bądź strategię ewolucyjną, który wygeneruje takie dane lub ścieżki, żeby:
- Pokryć jak największą liczbę ścieżek w grafie, ale tak, żeby te ścieżki się nie powtarzały,
- Pokryć wszystkie zdefiniowane cele np. konkretne węzły grafu,
- Generować dane testowe z pewnej populacji początkowej tak, aby któreś z rzędu pokolenie łącznie osiągnęło lepsze dopasowanie do rozwiązywanego problemu optymalizacji niż to, które jest zadane na jako populacja początkowa,
- Znaleźć takie testy z dostępnego zestawu testów, które powinny być przeprowadzone w pierwszej kolejności (nadawanie testom priorytetów za pomocą wag krawędzi, czyli osiąganie minimum lub maksimum w zależności od kontekstu).
- Podzielić zestaw danych wejściowych na podzbiory, w których elementy są w jakiś sposób do siebie podobne i zastosować optymalizację wielokryterialnej (dane rozwiązanie jest oceniane wg kilku kryteriów) w celu wygenerowania zestawu danych, który jest najlepszy względem rozwiązania postawionego problemu optymalizacji. Podział na podzbiory może odbywać się metodami grupowania danych znanymi w informatyce lub poprzez zastosowanie własnych opracowań podziału populacji na podzbiory [7],
- Wykorzystać sąsiedztwa sąsiedztwo wierzchołków w grafie DDG (graf w którym ważna jest ilość rozgałęzień, a nie węzły w ścieżce) do generowania danych wejściowych i wskazania takich, które generują ścieżki niezależne od innych ścieżek. Po stwierdzeniu, że wylosowana ścieżka jest niezależna, dodaje się odpowiednie dane do zestawu testów [1],
- Generować dane wejściowe lub zestawy testów do testowanie modułowego,
- Łączenie ewolucyjnego algorytmu z innymi algorytmami do generowania zestawy danych wejściowych, np. metoda K-means, Filtr Kalmana [2], [4],
- Napisać program z błędami i sprawdzić jaki procent błędów znajdzie algorytm ewolucyjny,
- Porównywać czasy wykonania algorytmów ewolucyjnych w testowaniu.
4. Zalety stosowania strategii ewolucyjnych w generowaniu danych testowych
Analiza poprzednich rozdziałów oraz publikacji zwłaszcza pozycji [20] pozwala wyciągnąć pewne wnioski oraz które wynikają z zastosowanie strategii ewolucyjnych w procesie generowania danych testowych. Najważniejsze zalety jakie narzucają się na myśl to:
Losowość ale taka, której kierunek jest kontrolowany za pomocą funkcji dopasowania oraz procesów ewolucyjnych (krzyżowanie). Istnieją generatory danych testowych, ale dzieje się to w sposób całkowicie niekontrolowany, tzn. że nie istnieje kryterium dopasowania danych do problemu. Może być wybrana tylko dziedzina dla generowanych danych testowych.
- Wprowadzanie mutacji, którą można potraktować jako czynnik, który pozwala wyeliminować zjawisko powtarzania pewnego schematu w generowaniu danych testowych,
- Metoda zastosowania algorytmu ewolucyjnego jest dość uniwersalna, więc nadaje się do generowania danych testowych w oparciu o różne modele funkcjonalności w systemach informatycznych. Dla każdego modelu matematycznego lub diagramu przypadków użycia można zastosować algorytm ewolucyjny w procesie dostarczania danych testowych,
- Metoda strategii ewolucyjnych jest stosunkowo szybka (co wynika z publikacji): znalezienie rozwiązania jest często możliwe po kliku iteracjach lub przeszukaniu niewielkiej części stanów,
- Odporność na paradoks pestycydów. Dzięki zastosowaniu strategii ewolucyjnej do wygenerowania danych wejściowych ryzyko takiego zjawiska znacznie zmaleje lub w ogóle nie wystąpi,
- Możliwość zdefiniowania funkcji dopasowania w taki sposób, aby wygenerowane dane testowe były bardzo związane z kontekstem użycia testowanego oprogramowania. Testowanie jest zależne od kontekstu, więc dane testowe również muszą być zależne od kontekstu użycia aplikacji,
- Optymalizacja wielokryterialna. Funkcja dopasowania, która wyznacza kierunek generowania nowego pokolenia (tutaj dane testowe) może być sumą kilku innych funkcji mierzących jakość, które mogą być przemnożone przez wagi. Daje to możliwość wygenerowania danych, które są poprawne dla kilku atrybutów związanych z danymi,
- Możliwość wprowadzania zmiennych kryteriów stopu algorytmu. W przypadku, gdy algorytm nie znajdzie zadowalającego rozwiązania, możliwa jest zmiana parametrów, które kontrolują proces generowania nowego pokolenia, co może poprawić jakość rozwiązania postawionego problemu. Takie postępowanie jest opisane dokładniej w książce "Sieci neuronowe, algorytmy genetyczne i systemy rozmyte" autorstwa Rutkowskich oraz Pilińskiego.
5. Podsumowanie
Celem napisania artykułu było przedstawienie ogólnego stanu badań naukowych i wyciągniętych wniosków z tych badań pod kątem zalet, jakie może dać stosowanie strategii ewolucyjnej w procesie generowania danych testowych. Publikacje na ogół zawierają proste przykłady zastosowania oraz małe odniesienie do praktyki, ponieważ nie są opisywane badania naukowe na systemach używanych np. przez firmy prywatne lub instytucje publiczne. Warto wobec tego próbować stosować takie strategie ewolucyjne w praktyce, przeprowadzając testy na systemach, które są w użyciu. Zainteresowanych dalszą analizą i pogłębieniem wiedzy z tego zakresu czytelników zachęcam do czytania pozycji wymienionych w bibliografii.
6. Bibliografia
[1] Ahmed S.G., Automatic generation of basis test paths using variable length genetic algorithm, Elsevier B.V. 2014,
[2] Alavi R., Lofti S., The New Approach for Software Testing Using a Genetic Algorithm Based on Clustering Initial Test Instances, International Conference on Computer and Software Modeling 2011,
[3] Alba E., Chicano F., Observations in using parallel and sequential evolutionary algorithms for automatic software testing, Computers & Operations Research 35 (2008),
[4] Aleti A., Grunske L., Test data generation with a Kalman filter-based adaptive genetic algorithm, The Journal of Systems and Software 103 (2015) 343–352,
[5] Alshraideh M., Mahafzah B., A., Al-Sharaeh S., A multiple-population genetic algorithm for branch coverage test data generation, Software Quality Journal 2011,
[6] Farley D., Humble J., Ciągłe dostarczanie oprogramowania, Helion 2015,
[7] Gong D., Tian T., Yao X., Grouping target paths for evolutionary generation of test data in paralel, The Journal of Systems and Software 2012,
[8] Gong D., Zhang Y., Generating test data for both path coverage and fault detection using genetic algorithms , Front. Comput. Sci., 2013,
[9] Gong D., Zhang Y., Generating test data for both path coverage and fault detection using genetic algorithms: multi-path case , Front. Comput. Sci., 2014,
[10] Harrold M. J., Pargas R. P., Peck R. R., Test-Data generation using genetics algorithms, Journal of Software Testing, Verification and Reliability 1999,
[11] Hermadi I., Lokan C., Sarker R., Dynamic stopping criteria for search-based test data generation for path testing , Information and Software Technology 56 (2014),
[12] Hudec J., Gramatova E., AN EFFICIENT FUNCTIONAL TEST GENERATION METHOD FOR PROCESSORS USING GENETIC ALGORITHMS, Journal of ELECTRICAL ENGINEERING, VOL. 66, NO. 4, 2015,
[13] Khurana N., Chillar R. S., Test Case Generation and Optimization using UML Models and Genetic Algorithm, 3rd International Conference on Recent Trends in Computing 2015 (ICRTC-2015),
[14] Kim H., Srivastava P. R., Application of Genetic Algorithm in Software Testing, International Journal of Software Engineering and Its Applications Vol. 3, No.4, October 2009,
[15] Krishnamoorthi R., Sahaaya Arul Mary S.A., Regression Test Suite Prioritization using Genetic Algorithms, International Journal of Hybrid Information Technology Vol.2, No.3, July, 2009,
[16] Mao C., Harmony search-based test data generation for branch coverage in software structural testing, Springer-Verlag London 2013,
[17] Mirzaaghaei M., Pastore F., Pezze M., Automatic test case evolution, SOFTWARE TESTING, VERIFICATION AND RELIABILITY 2014,
[18] Piaskowy A., Smilgin R., Dane Testowe, teoria i praktyka, Helion 2011,
[19] Roman A., Testowanie i jakość oprogramowania, PWN 2015,
[20] Rutkowska D., Piliński M., Rutkowski L., Sieci neuronowe, algorytmy genetyczne i systemy rozmyte, PWN W-wa 1997
O autorze
|
|
Marek Żukowicz jest absolwentem matematyki na Uniwersytecie Rzeszowskim. Obecnie pracuje jako tester. Jego zainteresowania skupiają się wokół testowania, matematyki, zastosowania algorytmów ewolucyjnych oraz zastosowania matematyki w procesie testowania. Interesuje się również muzyką, grą na akordeonach oraz na perkusji. |

Od redakcji