 Redakcja
Redakcja


Problem niestabilności testów automatycznych. Koszty i konsekwencje
Testy automatyczne miały być lekarstwem na dobrze znane bolączki projektowe. Miały zapewniać szybsze wykrywanie awarii, natychmiastową informację zwrotną, większe poczucie kontroli przy wdrożeniach. W praktyce bywa różnie. W codziennej pracy testerzy i programiści coraz częściej spotykają się z testami, które raz przechodzą, a raz nie, mimo braku zmian w kodzie czy środowisku. To właśnie flaky tests, czyli niestabilne testy, które potrafią skutecznie podważyć zaufanie do całego procesu automatyzacji.
Niestabilne testy mogą stać się czynnikiem paraliżującym rozwój produktu. Spowalniają pipeline'y, marnują czas i zasoby, a w skrajnych przypadkach prowadzą do sytuacji, w których testy przestają być brane na poważnie, co przekłada się bezpośrednio na jakość oprogramowania.
Co sprawia, że test staje się niestabilny?
Główny problem to nieprzewidywalność. Ten sam test w tych samych warunkach raz zwraca rezultat passed, a innym razem failed. Powody bywają różne, ale najczęściej źródło problemu leży w jednej (lub kilku) z poniższych kategorii:
- defekt w kodzie testowanego oprogramowania lub w kodzie testującym, w ramach którego wynik testu zależy od nieprzewidywalnej kolejności, w jakiej więcej niż jeden wątek lub proces uzyskują dostęp do współdzielonych zasobów i je modyfikują (ang. race conditions)
- zależności od danych zewnętrznych albo usług trzecich,
- niewłaściwa synchronizacja (test "nie czeka" wystarczająco długo na elementy UI),
- timeouty niedopasowane do środowiska,
- współdzielone dane lub stany, które powodują interferencje między testami,
- błędy w implementacji samych testów,
- brak izolacji środowiskowej,
- losowość w testowanej logice lub danych wejściowych.
Wiele z tych problemów nie jest oczywistych i objawiają się one dopiero przy dużej skali lub w specyficznych warunkach środowiskowych. Dlatego tak ważne jest systematyczne podejście do analizy przyczyn podstawowej.
Przykład narzędzia do walki z niestabilnością
Narzędzia próbują radzić sobie z tym problemem na wielu płaszczyznach – od poziomu projektowania, przez architekturę po wsparcie AI na poziomie analizy wyników.
Swoją metodę ma też Azure DevOps, który oferuje wbudowane mechanizmy, które wspierają zespoły w identyfikowaniu i kontrolowaniu flaky tests. Dzięki temu można szybciej reagować na problemy i zarządzać nimi w całym cyklu życia testów.
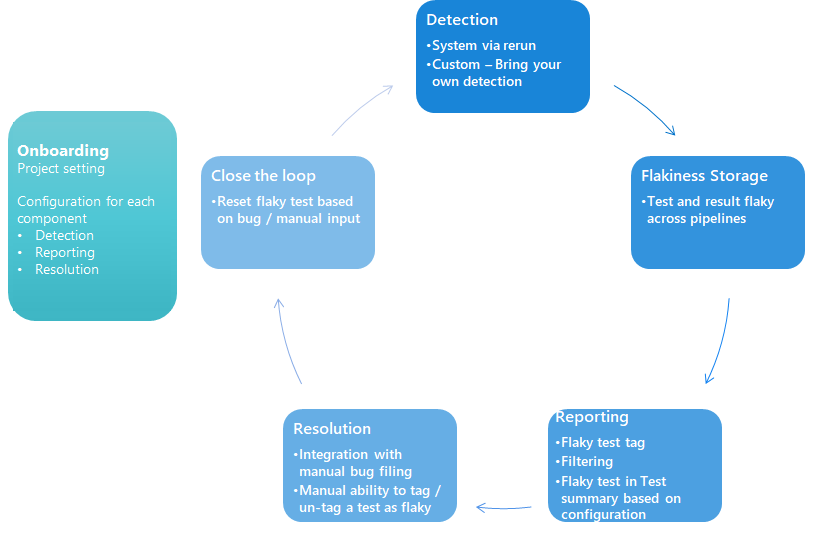
Wykrywanie niestabilności
Azure udostępnia dwa główne podejścia do identyfikowania testów niestabilnych:
- Wykrywanie systemowe - polega na automatycznym ponownym uruchamianiu testów, które zakończyły się niepowodzeniem. Jeśli test raz zawodzi, a innym razem przechodzi - system automatycznie oznacza go jako niestabilny. To proste i skuteczne rozwiązanie, niewymagające dodatkowej konfiguracji.
- Wykrywanie niestandardowe - pozwala zintegrować własne mechanizmy detekcji, co sprawdza się zwłaszcza przy złożonych scenariuszach lub nietypowych przypadkach, których nie wychwyci prosty retry.
Zarządzanie informacją o niestabilności
Azure umożliwia centralne zarządzanie informacją o testach oznaczonych jako niestabilne. Co to oznacza w praktyce? Każdy pipeline korzystający z tej samej gałęzi ma dostęp do tej samej informacji, dzięki czemu nikt nie traci czasu na ponowne debugowanie testu, który już został rozpoznany jako problematyczny.
Kontrola wpływu na CI/CD
Azure DevOps pozwala zdecydować, jak niestabilne testy mają wpływać na status kompilacji:
- można uwzględnić je w ogólnym procencie testów zaliczonych (domyślna opcja),
- można wyłączyć ich wpływ na wynik builda - pipeline nie zostanie zablokowany przez test oznaczony jako niestabilny,
- każdy flaky test zostaje oznaczony specjalnym tagiem, co umożliwia jego łatwe filtrowanie i dalszą analizę.
Wspieranie procesu naprawy
Po wykryciu niestabilności, Azure umożliwia:
- ręczne oznaczanie testów jako niestabilnych (np. po analizie ręcznej),
- resetowanie statusu flaky po naprawie,
- integrację z systemem zgłoszeń defektów, co ułatwia monitorowanie procesu naprawczego.
Jak eliminować niestabilność testów
Sam mechanizm wykrywania niestabilnych testów to dopiero początek. Ważne jest wdrożenie strategii, która pozwoli na ich skuteczne ograniczanie i kontrolowanie. Oto sprawdzony plan działania, który można oprzeć na funkcjonalnościach dostępnych w Azure DevOps:
- Włącz wykrywanie niestabilnych testów. Zacznij od aktywacji funkcji zarządzania flaky tests w ustawieniach projektu. Wybierz metodę detekcji najlepiej dopasowaną do Twojego kontekstu - systemową lub własną.
- Zdefiniuj politykę zespołu. Ustal, czy testy oznaczone jako niestabilne mają blokować pipeline, czy jedynie być raportowane. Na początku warto zdecydować się na opcję mniej inwazyjną, by nie zatrzymywać procesu wdrożeniowego przy pierwszych oznakach problemów.
- Kategoryzuj i priorytetyzuj. Nie wszystkie flaky tests są równie groźne. Oceń, które testy weryfikują kluczowe funkcje i nadaj im odpowiedni priorytet. Dzięki temu unikniesz sytuacji, w której zespół skupia się na problemach drugorzędnych.
- Analizuj systemowo, nie punktowo. Zamiast reagować na każdy przypadek osobno, szukaj wzorców. Wiele testów może mieć wspólną przyczynę, np. źle zaprojektowany helper, współdzielone dane testowe czy problemy z infrastrukturą testową.
- Refaktoryzuj z myślą o stabilności. Przy naprawianiu flaky tests sięgaj po sprawdzone praktyki: mechanizmy retry, wyraźne warunki oczekiwania, izolowane środowiska testowe, stabilne dane wejściowe. Test ma nie tylko sprawdzać działanie funkcji, ale też być odporny na zmienność środowiska.
- Monitoruj trend. Śledź zmiany liczby niestabilnych testów w czasie. Jeśli ich liczba rośnie mimo napraw, może to oznaczać głębszy problem, np. z architekturą systemu, testów lub pipeline’u. Reaguj wcześniej, zanim niestabilność wymknie się spod kontroli.
Konfiguracja krok po kroku w Azure DevOps
Dla tych, którzy chcą od razu przejść do działania, podajemy konkretne kroki konfiguracji zarządzania niestabilnymi testami w Azure DevOps:
- Przejdź do Ustawienia projektu w swoim projekcie Azure DevOps.
- W panelu po lewej stronie znajdziesz sekcję Procesy. Wybierz z niej opcję Zarządzanie testami.
- Ustaw przełącznik Wykrywanie niestabilnych testów w pozycję „Włączone”.
- Wybierz preferowaną metodę wykrywania. Masz do dyspozycji dwa warianty:
- wykrywanie systemowe - wykorzystuje mechanizm automatycznego ponownego uruchamiania testów
- wykrywanie niestandardowe - umożliwia integrację z własnymi rozwiązaniami identyfikującymi flaky tests.

- Zdecyduj, czy chcesz włączyć wykrywanie niestabilności we wszystkich pipeline’ach, czy tylko w wybranych.
- Skonfiguruj raportowanie i uprawnienia:
- wybierz, czy testy oznaczone jako niestabilne mają być wliczane do ogólnego wyniku testów
- zdecyduj, czy użytkownicy mogą ręcznie oznaczać i odznaczać testy jako niestabilne.

Po zapisaniu ustawień system automatycznie zacznie oznaczać testy, które wykazują oznaki niestabilności. Dzięki temu zespół zyska lepszą widoczność problemów i będzie mógł szybciej reagować na ich źródła, bez powtarzania tych samych analiz w nieskończoność.
Warto pamiętać, że funkcja zarządzania niestabilnymi testami jest obecnie dostępna tylko w Azure DevOps Services (wersja chmurowa), a nie w Azure DevOps Server (wersja lokalna). Jak większość nowych funkcji, prawdopodobnie trafi do wersji serwerowej w kolejnym głównym wydaniu.
Podsumowanie
Niestabilne testy nie są czymś wyjątkowym i celem nie musi być ich całkowita eliminacja (choć oczywiście warto do tego dążyć), ale przede wszystkim świadome zarządzanie ich wpływem na proces wytwarzania oprogramowania. Narzędzia dają konkretne, praktyczne rozwiązania, które wspierają zespoły na każdym etapie: od wykrywania niestabilności, przez kontrolę wpływu na pipeline, aż po dokumentowanie i analizę problemów.

















