Michał Zacharuk
Michał Zacharuk


Istotnym aspektem badania API są testy negatywne. Deweloperzy korzystający z API w celu pozyskania dostępu do zewnętrznych usług w stosunku do kodu nad którym pracują, potencjalnie mogą próbować użyć API niezgodnie z ich przeznaczeniem. Aby zmniejszyć ryzyko wystąpienia takiej sytuacji stosuje się skomplikowane mechanizmy obsługi błędów. Przykładem takiego działania może być wykonanie testów kombinatorycznych dla różnych interfejsów, ze względu na to, że API są bardzo często używane równocześnie, a każde z nich może charakteryzować się rożnymi parametrami, których wartości można połączyć ze sobą na wiele sposobów. Ponadto API zazwyczaj cechują się tym, że są ze sobą luźno powiązane, co podwyższa prawdopodobieństwo wystąpienia utraty transakcji czy zakłóceń czasowych. Ważne jest zatem, aby przetestować takie mechanizmy jak ponawianie i odtwarzanie.
Kolejnym bardzo ważnym aspektem jest zapewnienie wysokiej dostępności usług przez organizację, która udostępnia API. Można zdefiniować ją jako stopień, w którym system działa i jest dostępny, kiedy wymagane jest jego użycie. Ta charakterystyka jakości najczęściej wyrażana jest w procentach. Wysoka dostępność jest kluczowa w przypadku testowania wydajności API, ponieważ, gdyby wskazany system miał przerwy w działaniu mogłoby to doprowadzić do zebrania niepoprawnych i nie oddających rzeczywistości wyników (pokazanie tzw. „false negative” czyli fałszywie negatywne wyniki) lub do braku możliwości przeprowadzenia testów.
W kontekście dostępności należy zaznaczyć również, że współdziałanie i integracja zarówno serwerów, komunikacji sieciowej, przepustowości sieci, baz danych czy konkurencji o zasoby na serwerze (procesory, pamięć, operacje dyskowe) są często wąskimi gardłami, które można wykryć testując m.in. wydajność oprogramowania.
Specyfika testowania wydajności API
Testy wydajności API są wykonywane za pomocą specjalistycznych narzędzi wspierających automatyzację, ponieważ ręczne wykonanie ich jest niemożliwe. Aby sprawdzić wydajność API należy zasymulować jednoczesne odpytywanie serwera przez klienta. W niniejszej pracy zaprojektowano kilka przypadków testowych, które pokrywają funkcjonalności wybranego programowalnego interfejsu aplikacji.
W tego typu testach trzeba zadbać o wiele różnych aspektów technicznych, m.in.:
- symulacje jednoczesnych użytkowników korzystających z aplikacji,
- wprowadzenie asercji i sprawdzeń czy wykonany test zakończył się powodzeniem,
- założenie odpowiednich progów i metryk, które w raporcie odpowiedzą czy aplikacja spełnia założone oczekiwania,
- czas odpowiedzi serwera w milisekundach,
- kody odpowiedzi HTTP,
- informacje o zużyciu sprzętowym serwera,
- synchronizację pomiędzy żądaniami, np. sekwencyjność poszczególnych kroków i przekazywanie parametrów.
Odpowiedni dobór narzędzia zapewnia dostęp do tych metryk oraz umożliwia analizę danych, na podstawie których można wyciągnąć wnioski odnośnie wydajności testowanego API.
Narzędzie do testów wydajności API – JMeter
Apache JMeter jest narzędziem napisanym w Javie typu open-source na licencji Apache License 2.0. Stosowany jest głównie do wykonywania testów wydajności aplikacji internetowych. Zostało ono wybrane do tego projektu ze względu na zbiór koniecznych do których należą:
- możliwość wykonywania testów wydajności i obciążenia dla wielu różnych aplikacji / serwerów / typów protokołów:
- web - HTTP, HTTPS (Java, NodeJS, PHP i wiele innych),
- usługi internetowe (ang. webservices) SOAP / REST,
- tryb CLI (Command-line) w celu uruchamiania testów wydajności z dowolnego środowiska i systemu operacyjnego kompatybilnego z Javą (Linux, Windows, Mac OSX, …),
- dynamiczne raporty HTML,
- możliwość wydobycia danych z najbardziej popularnych formatów odpowiedzi serwera: HTML, JSON, XML, lub inny dowolny format tekstowy,
- całkowitą przenaszalność,
- pełną strukturę wielowątkową, która umożliwia próbkowanie przez wiele wątków i jednoczesne próbkowanie różnych funkcji przez oddzielne grupy wątków,
- rozszerzalność poprzez dodatkowe wtyczki:
- rozszerzenia Samplerów umożliwiają nieograniczone możliwości testowania,
- wtyczki do analizy danych i wizualizacji umożliwiają dużą rozszerzalność i personalizację,
- funkcje mogą być użyte do dostarczenia dynamicznych danych wejściowych do testów lub możliwość manipulacji danymi.
Na JMetera składają się następujące elementy, które zostaną użyte w części praktycznej tej pracy:
- Test plan – podstawowy element, który przechowuje konfigurację testową oraz umożliwia uruchomienie testów.
- Grupa wątków (ang. Thread Group) – element kontrolujący liczbę wątków wykonujących testy. Każdy wątek reprezentuje działanie jednego użytkownika.
- Kontrolery (ang. Controllers) – zapewniają kontrolę and testami. Składają się na nie:
- Samplery (ang. Samplers) – umożliwiają wysyłanie żądań do serwera, np. „HTTP Request Sampler” umożliwia wysłanie żądania http. Wykonywane są w kolejności takiej w jakiej widnieją w drzewie projektu.
- Kontrolery logiczne (ang. Logic Controllers) – pozwalają na kontrolowanie logiki testów, czyli np. wysyłanie żądań do serwera tylko po spełnieniu określonego warunku.
- Nasłuchiwacze (ang. Listners) – umożliwiają zebranie rezultatów wykonanych testów zarówno w formie tekstowej jak i graficznej.
- Opóźnienia (ang. Timers) – stosowane głównie do opóźnienia wysyłanych żądań do serwera.
- Asercje (ang. Assertions) – pozwalają określić czy oczekiwana odpowiedź z serwera jest poprawna.
- Elementy konfiguracyjne (ang. Configuration Elements) – elementy ściśle współpracujące z Samplerami, umożliwiają m.in. zarządzanie nagłówkami http przesyłanymi wraz z żądaniami do serwera.
- Postprocesory (ang. Post-Processor Elements) – dają możliwość wykonania akcji tuż po zakończeniu działania Samplera. Stosowane np. do odczytywania danych z odpowiedzi żądania oraz zapisywania tych danych do zmiennych celem późniejszego użycia w następnym żądaniu.
Wszystkie powyższe pozwalają na optymalne przeprowadzenie testów wydajności API w środowisku rozproszonym.
Rozproszone testy API
Architektura master – slave jest pierwszym krokiem w kierunku rozproszonego testowania, którego przykład zobrazowano na rys. 6. Składają się na nie maszyny, które w zależności od przeznaczenia przyjmują role sterującą (master) oraz wykonującą (slave). Przy konfiguracji narzędzia JMeter na każdej maszynie typu slave musi zostać uruchomiony serwer za pomocą pliku jmeter-server.bat.
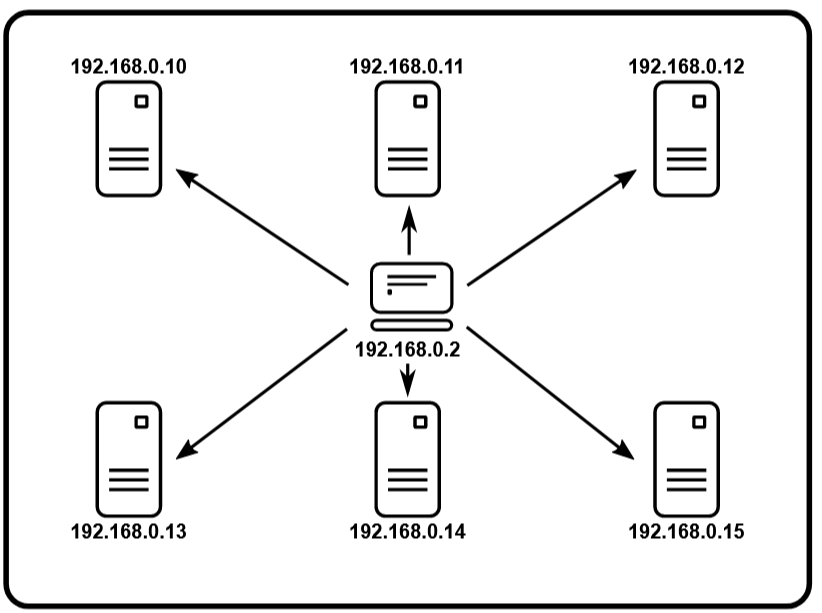
Rys. 6 Schemat architektury master-slave
(źródło: https://jmeter.apache.org/usermanual)
W celu prawidłowego funkcjonowania maszyny typu slave należy zapewnić kilka warunków:
- zarówno na maszynie master jak i slave musi być ta sama wersja oprogramowania JMeter,
- na maszynie slave w pliku jmeter.properties należy dodać wpis:
- server.rmi.ssl.disable=true,
- na maszynie typu master w pliku jmeter.properties należy ustawić poprawnie parametr remote_hosts z adresem IP maszyny typu slave,
- systemowy firewall musi być wyłączony lub odpowiednie porty muszą być otwarte,
- wszystkie maszyny klienckie muszą znajdować się w tej samej podsieci,
- ta sama wersja Javy oraz aplikacji JMeter musi znajdować się na wszystkich maszynach.
Jak może wyglądać schemat testów rozproszonych w JMeter przestawiono na rys. 7. „Controller node” nazywany również jako master – stacja robocza znajdująca się w centrum, kontroluje pozostałe maszyny, czyli „Worker node” inaczej także slave. Na stacjach typu „Worker node” musi być uruchomiony jmeter-server, który przyjmuje wszystkie polecenia wydane z głównego kontrolera i wysyła żądania do aplikacji, która podlega testom.
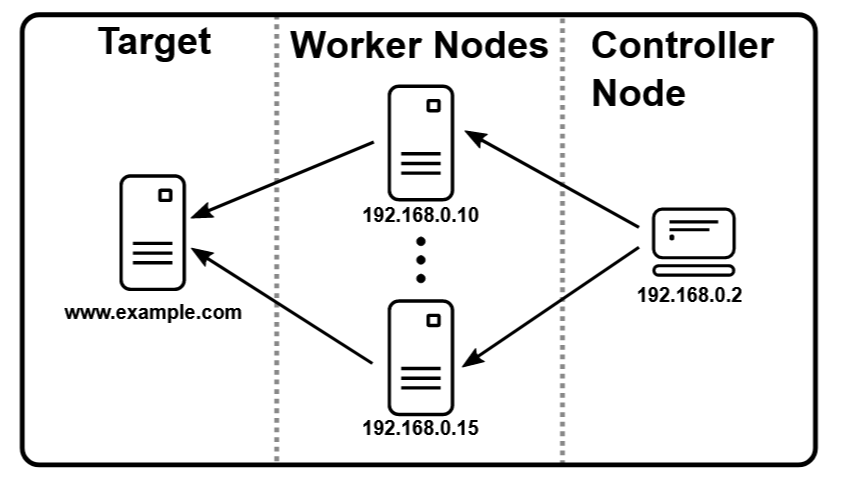
Rys. 7 Testy rozproszone w JMeter
(źródło: https://jmeter.apache.org/usermanual)
Działania przedstawione w tej pracy są demonstracją testowania wydajności aplikacji w środowisku rozproszonym. Konfiguracja w wersji uproszczonej przedstawiona jest na rys. 8. Ze wskazanego schematu można odczytać, że kontroler, czyli „JMeter Master” wysyła sygnały do stacji roboczej „JMeter Slave”, która następnie generuje zaplanowane obciążenie względem testowanej aplikacji „Restful-booker”.
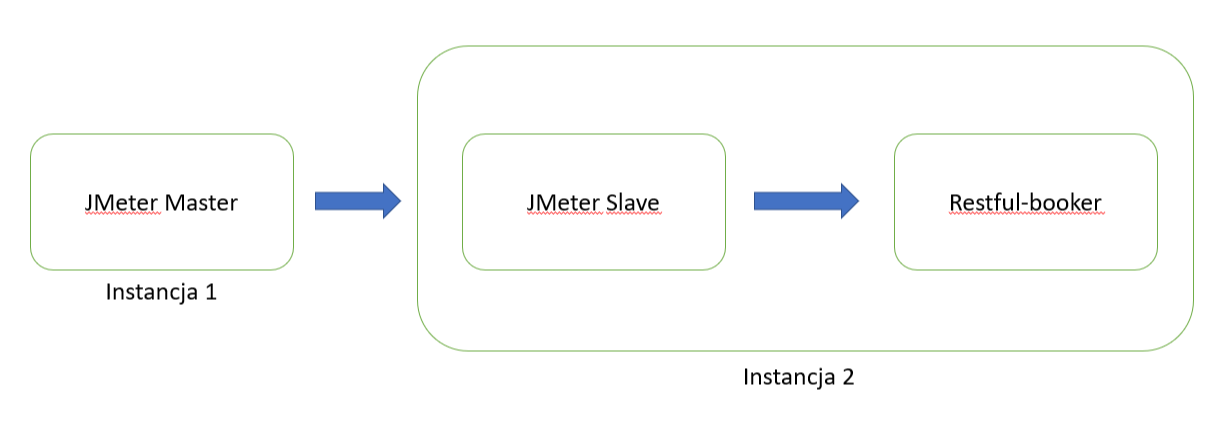
Rys. 8 Architektura środowiska przeprowadzonych testów
Do zalet wykorzystanej architektury można zaliczyć to, że zbudowany system do testów wydajności jest łatwo rozszerzalny. Jeśli zajdzie taka potrzeba, wystarczy dodać kolejny serwer sterowany z poziomu kontrolera i przekierować na niego część generowanego ruchu skierowanego na testowaną aplikacje. Dzięki czemu będzie można dociążyć jeszcze bardziej docelowe oprogramowanie. Sugerowana w testach przeprowadzonych w tej pracy konfiguracja jest jedynie przykładem jak może wyglądać zestaw maszyn służących do wykonania testów wydajności. Rozbudowa środowiska o kolejne komputery lub maszyny wirtualne daje możliwość zwiększenia poziomu obciążenia. Należy podkreślić, że w najprostszej konfiguracji zarówno kontroler jak i serwer generujący obciążenia mogą być zainstalowane na jednej instancji.
Ze względu na uproszczenia zastosowane w tej pracy spowodowane ograniczonym budżetem i zasobem sprzętowym zarówno slave jak i aplikacja poddana testom znajduje się na jednej fizycznej maszynie, co wiąże się z pewnym ryzykiem związanym ze zbieranymi danymi – ryzyko wystąpienia efektu próbnika. Definicja tego pojęcia mówi o tym, że użycie narzędzia do testów wydajnościowych może mieć nieznaczny wpływ na zebrane metryki i działanie testowanego systemu przez wzgląd na to, że również zużywa ono zasoby sprzętowe. Ponieważ testowana aplikacja oraz generator obciążenia zainstalowane są na tej samej maszynie to muszą one współdzielić zasoby sprzętowe w tym procesor, pamięć RAM czy pamięć dyskową. Czym większe obciążenie generujemy tym mniej zasobów zostaje dla testowanej aplikacji.
W przypadku testów linii podstawowej nie ma to większego wpływu, ale już metryki w przypadku uruchomienia testów przeciążających mogą być zaburzone. Pomimo opisanego ryzyka, zastosowane rozwiązanie konfiguracyjne jest uproszczeniem powszechnie stosowanym w praktyce testowania. W środowisku testowym często wprowadza się uproszczone konfiguracje, szczególnie we wstępnych etapach testów. Wynika to zazwyczaj z oszczędności budżetowych. Dopiero testy przedprodukcyjne lub testy na środowisku zbliżonym do produkcyjnego lub produkcyjnym dają pełne odwzorowanie realnego, końcowego środowiska pracy aplikacji. Można założyć, że informacja o potencjalnych awariach wydajności w środowisku testowym może wskazywać na duże prawdopodobieństwo wystąpienia takich problemów w środowisku produkcyjnym, a brak awarii w testach na środowiskach testowych nie jest jednoznaczny z brakiem awarii również na produkcji.
Część pierwszą pracy znajdziesz tutaj.
*) Od autora pracy:
"Z niniejszej publikacji usunięto wstęp związany ściśle z zagadnieniem samego testowania oprogramowania. Nacisk tej publikacji skierowany jest na testy wydajności wraz ze sprawozdaniem z przebiegu wykonania tych prac. Pomysł na temat obrony dyplomu i publikacji tego artykułu był prosty – ja jako autor chciałem nauczyć się nowej umiejętności w moim testerskim przyborniku, a z wami czytelnikami chciałem podzielić się efektem mojej kilkumiesięcznej pracy, na którą złożyła się nauka testowania wydajności od zupełnych podstaw, przez implementację rozwiązania w JMeter, a także stworzenie raportu. Cel został osiągnięty poprzez znalezienie wielu źródeł w postaci teorii testowania wydajności, a przede wszystkim znalezieniu informacji na temat dobrych praktyk i przykładów jak zaplanować i wykonać tego typu testy. Puentą jest to, jak to w projekcie informatycznym, czyli dostarczenie pewnej wartości w postaci przeprowadzenia i wykonaniem testów wydajności wraz z raportem i wnioskami. Z perspektywy czasu wiele rzeczy bym zmienił, natomiast myślę, że ten artykuł może komuś jeszcze posłuży."
*) Publikacja ta jest skróconą wersją pracy dyplomowej.
Autor: Michał Zacharuk
Tytuł pracy: "Testowanie wydajności API w środowisku rozproszonym"
Uczelnia: Politechnika Łódzka, Wydział Elektrotechniki, Elektroniki, Informatyki i Automatyki
Instytut Informatyki Stosowanej
Opis: Przedstawienie i rozwiązanie problemu testowania wydajności aplikacji internetowej opartej na REST API w środowisku rozproszonym. Skrócona wersja pracy dyplomowej.