Redakcja
Redakcja


Chaos engineering jest metodą testowania, która polega na przeprowadzaniu kontrolowanych eksperymentów w celu weryfikacji odporności systemów na nieprzewidziane sytuacje. W przeciwieństwie do tradycyjnego testowania nie skupiamy się tutaj na sprawdzaniu, czy system działa poprawnie w idealnych warunkach, ale na tym, jak zachowa się w obliczu różnorodnych awarii i problemów. Wyobraźmy sobie system jak żywy organizm - nie wystarczy sprawdzić, czy funkcjonuje prawidłowo w idealnych warunkach laboratoryjnych. Musimy wiedzieć, jak poradzi sobie w sytuacjach stresowych, przy zwiększonym obciążeniu czy w przypadku awarii poszczególnych komponentów.
Głównymi punktami inżynierii chaosu są:
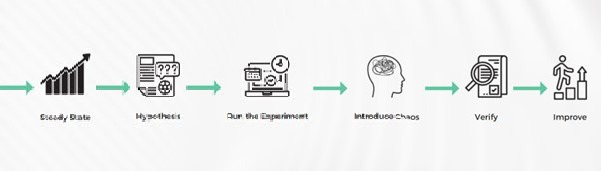
- zdefiniowanie stanu normalnego - przed rozpoczęciem eksperymentów należy dokładnie określić, jak system powinien działać w normalnych warunkach
- tworzenie hipotez - sformułowanie przypuszczeń dotyczących zachowania systemu w przypadku wystąpienia określonych problemów
- kontrolowane eksperymenty - przeprowadzanie testów w sposób, który minimalizuje ryzyko dla użytkowników końcowych
- monitorowanie i analiza - szczegółowa obserwacja zachowania systemu podczas eksperymentów
- ciągłe doskonalenie - wykorzystywanie zdobytej wiedzy do wzmacniania odporności systemu
Chaos engineering na przykładzie Netflix
Netflix, który jest pionierem chaos engineering, świetnie obrazuje filozofię stojącą za tą metodologią poprzez prostą analogię: Wyobraź sobie, że złapałeś gumę w samochodzie. Nawet jeśli masz zapasowe koło w bagażniku, czy wiesz, czy jest napompowane? Czy masz narzędzia do jego wymiany? A co najważniejsze, czy pamiętasz, jak prawidłowo wymienić koło? Jednym ze sposobów, aby upewnić się, że poradzisz sobie z przebitą oponą na autostradzie, w deszczu, w środku nocy, jest... celowe przebicie opony raz w tygodniu na swoim podjeździe w niedzielne popołudnie i przećwiczenie całej procedury wymiany. W rzeczywistym świecie byłoby to kosztowne i czasochłonne, ale w chmurze może być (prawie) darmowe i zautomatyzowane.
Idea Simian Army
Nazwa "Chaos Monkey" - pierwszego narzędzia z rodziny Simian Army - wzięła się z pomysłu wypuszczenia dzikiej małpy z bronią w centrum danych (lub regionie chmury), która losowo niszczy instancje i przegryza kable - wszystko to podczas gdy firma nadal obsługuje klientów bez przerw w działaniu. Sukces tego narzędzia zainspirował Netflix do stworzenia całej "armii małp", gdzie każda spełnia specyficzną rolę:
- Latency Monkey - wprowadza sztuczne opóźnienia w komunikacji client-server poprzez warstwę RESTful, symulując degradację usług. Może symulować zarówno drobne opóźnienia, jak i całkowitą niedostępność usługi bez faktycznego wyłączania instancji
- Conformity Monkey - wyszukuje instancje, które nie przestrzegają najlepszych praktyk (np. nie należą do grupy auto-skalowania) i wyłącza je, dając właścicielom usługi szansę na prawidłowe ponowne uruchomienie
- Doctor Monkey - monitoruje stan zdrowia każdej instancji poprzez health checki oraz zewnętrzne wskaźniki (np. obciążenie CPU). Wykryte „unhealthy” instancje są usuwane z użycia i ostatecznie terminowane po czasie danym właścicielom na znalezienie przyczyny problemu
- Janitor Monkey - dba o czystość i efektywność środowiska chmurowego, wyszukując i usuwając nieużywane zasoby
- Security Monkey - rozszerzenie Conformity Monkey, które znajduje naruszenia bezpieczeństwa lub luki (np. nieprawidłowo skonfigurowane grupy bezpieczeństwa AWS). Sprawdza również ważność certyfikatów SSL i DRM
- 10-18 Monkey (od Localization-Internationalization) - wykrywa problemy konfiguracyjne i runtime w instancjach obsługujących klientów w różnych regionach geograficznych, używających różnych języków i zestawów znaków
- Chaos Gorilla - symuluje awarię całej strefy dostępności Amazon AWS, weryfikując czy usługi automatycznie równoważą się w funkcjonalnych strefach bez widocznego wpływu na użytkownika i bez ręcznej interwencji.
Netflix podkreśla, że chmura opiera się na redundancji i odporności na awarie. Ponieważ żaden pojedynczy komponent nie może zagwarantować 100% dostępności (a nawet najdroższy sprzęt w końcu zawodzi), architektura chmury musi być zaprojektowana tak, aby awaria pojedynczych komponentów nie wpływała na dostępność całego systemu. Uruchamiając narzędzia typu Chaos Monkey w środku dnia roboczego, w starannie monitorowanym środowisku, z inżynierami gotowymi do rozwiązania ewentualnych problemów, firma może poznać słabości swojego systemu, zbudować automatyczne mechanizmy naprawcze, przygotować się na rzeczywiste awarie i minimalizować lub eliminować wpływ problemów na użytkowników.
Kiedy warto wprowadzić chaos engineering?
Chaos engineering sprawdzi się szczególnie w dużych, rozproszonych systemach, aplikacjach działających w chmurze, systemach wymagających wysokiej dostępności czy w środowiskach z wieloma mikrousługami. Natomiast może nie być najlepszym wyborem dla małych aplikacji desktopowych, systemów o niskim priorytecie biznesowym, środowisk, gdzie sporadyczne przestoje (ang. occasional downtime) są akceptowalne i aplikacji w fazie wczesnego rozwoju.
Jak zacząć implementację chaos engineering w procesie testowym? Warto zacząć od małych eksperymentów, bez konieczności symulowania katastrofalnych awarii. W kolejnym kroku należy przygotować monitoring, upewniając się, że mamy odpowiednie narzędzia do śledzenia zachowania systemu. Chaos engineering wymaga współpracy różnych specjalistów, którzy działają zgodnie z ustalonymi procesami awaryjnymi, reagując na rzeczywiste problemy i dokładnie dokumentując wyniki eksperymentów i swoje wnioski.
Korzyści z wdrożenia chaos engineering:
- zwiększona odporność systemu, lepsze przygotowanie na rzeczywiste awarie
- szybsza reakcja na incydenty, zespół jest lepiej przygotowany na różne scenariusze
- lepsza komunikacja, ze względu na to, że eksperymenty wymuszają współpracę między zespołami
- większe zaufanie i pewność, że system poradzi sobie w trudnych sytuacjach
- redukcja kosztów, ponieważ zapobieganie poważnym awariom jest tańsze niż ich naprawianie
Podsumowanie
Chaos engineering to podejście do testowania, które może znacząco poprawić niezawodność systemów. Wymaga jednak przemyślanego podejścia, odpowiedniego przygotowania i świadomości zarówno korzyści, jak i potencjalnych ryzyk.
Pamiętajmy, że celem nie jest wprowadzanie chaosu dla samego chaosu, ale kontrolowane eksperymenty, które pozwolą nam lepiej zrozumieć i ulepszyć systemy. W świecie, gdzie każda minuta przestoju może kosztować fortunę, takie podejście staje się nie luksusem, a koniecznością.