Redakcja
Redakcja


Dlaczego mielibyśmy separować dane od testów? Ponieważ pozwala nam to projektować pojedyncze testy, które mogą zostać wielokrotnie uruchomione z różnymi zestawami danych. Takie podejście znane jest jako testowanie sterowane danymi.
Jeśli dane na twardo podamy w teście, to uruchomimy go jednokrotnie. Gdy zdecydujemy się na przygotowanie jednego testu z pojedynczym zestawem danych, to może istnieć ryzyko, że stworzymy dziesiątki, a nawet setki testów o tej samej logice i różnych danych. Taka dokumentacja testowa, nie dość, że będzie rozbudowana, to również będzie trudna w utrzymaniu lub aktualizacji.
Odłączając dane od testów, możemy rozwijać zestawy danych niezależnie od samego testu, co sprawia, że nowe, ciekawe zbiory nie powodują konieczności powstania nowych testów, a jedynie zaktualizowania źródła z danymi.Pamiętając, że dane mogą pochodzić z wielu źródeł, wyróżnienie warstwy danych daje nam możliwość bardziej kreatywnego zasilania testów. Mogą to być pliki (XML, XLS), funkcje generacji danych lub dedykowane do tego narzędzia przygotowania danych testowych.
Koncept odseparowania danych wymaga kilku dodatkowych założeń. Przede wszystkim, tworzymy wysokopoziomowe przypadki, które nie mają ani danych, ani oczekiwanych rezultatów. Takie podejście pozwala nam jednocześnie projektować testy pozytywne, bazujące na danych, które powinny być w systemie przetworzone poprawnie oraz testy negatywne, które bazując na danych, nie powinny być przez system akceptowane - zwracają komunikaty błędów.
PRZYKŁAD
Funkcja: walidacja numeru telefonu klienta.
Test: czy walidacja działa poprawnie?
Dane testowe pozytywne: 123 456 789, (+48) 345123123, 0605763512
Dane testowe negatywne: aaa, #$, 3dj2023d2
Uruchomienie testu powinno pokazać, że dla danych pozytywnych walidacja przepuszcza prawdziwe numery telefonu, a dla danych negatywnych blokować ich możliwość zapisania.
Czasami istnieje możliwość, aby te same dane testowe były używane w różnych testach, np. test zakładania klienta (PT1) i testu aktualizowania danych klienta (PT2). Oczywiście z założeniem, że nie posługujemy się tym samym zestawem testów, w tym samym uruchomieniu.
PRZYKŁAD
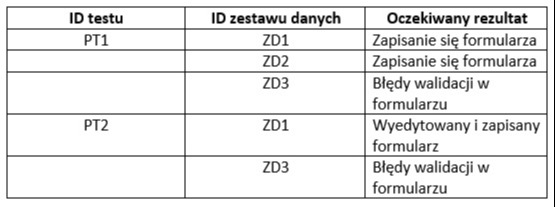
Widzimy więc szereg optymalizacji w projektowaniu testów i danych testowych, w tym:
- krótsza dokumentacja testów,
- prostsza dokumentacja testów,
- możliwość osobnego rozwijania testów i danych,
- niepowielanie testów,
- niepowielanie danych,
- możliwość użycia tych samych danych na wielu poziomach testowania (np. w dane z testów jednostkowych użyte przy testach API).
Takie podejście sprawdza się zarówno w testowaniu manualnym, jak i na każdym poziomie automatyzacji testów od testów jednostkowych po testy end-to-end.