Redakcja testerzy.pl
Redakcja testerzy.pl


Testowanie oprogramowania wiąże się z dużą odpowiedzialnością. Z jednej strony tester dba o jakość działania aplikacji, z drugiej powinien także zadbać o ochronę prywatnych danych użytkowników. To drugie wyzwanie nabiera szczególnego znaczenia, gdy w procesie testowym pojawiają się rzeczywiste dane osobowe. Wykorzystywanie prawdziwych danych poza ich pierwotnym celem może wiązać się z niezgodnym z prawem ich przetwarzaniem, a to grozi poważnymi konsekwencjami.
Regulacje prawne
W Polsce i całej Unii Europejskiej podstawowym dokumentem regulującym podejście do danych osobowych jest RODO. Rozporządzenie nie tylko nakłada obowiązek ochrony danych, ale wręcz wymaga regularnego testowania skuteczności stosowanych zabezpieczeń. RODO szeroko definiuje dane osobowe jako każdą informację, która pozwala zidentyfikować osobę. W testach mogą to być np. imiona i nazwiska, numery PESEL, adresy e-mail, ale też dane wrażliwe, takie jak informacje o zdrowiu czy dane biometryczne.
Jedną z podstawowych zasad, którą trzeba brać pod uwagę, jest minimalizacja danych. Oznacza to korzystanie wyłącznie z tych informacji, które są niezbędne do przeprowadzenia testów. Równocześnie ciąży na testerach obowiązek informacyjny wobec osób, których dane są wykorzystywane, bo naruszenie zasad RODO może słono kosztować (maksymalna kara to nawet 20 milionów euro lub 4% globalnego obrotu firmy).
Poza RODO, znaczenie mają również inne przepisy, np. ustawa o krajowym systemie cyberbezpieczeństwa, wybrane artykuły Kodeksu karnego czy branżowe regulacje, jak rekomendacje KNF dla sektora finansowego.
Wyzwań związanych z prywatnością w testowaniu oprogramowania jest więc sporo. Jednym z podstawowych jest zarządzanie danymi testowymi. Z jednej strony chcemy unikać używania danych produkcyjnych, z drugiej testy muszą być realistyczne. W tym kontekście często pojawia się temat danych syntetycznych, które niwelują ryzyko wycieku, ale wymagają dodatkowych zasobów i umiejętności. Omówimy je w dalszej części artykułu.
Często pomijanym aspektem jest też bezpieczeństwo środowisk testowych. Zdarza się, że są one znacznie słabiej zabezpieczone niż środowiska produkcyjne, co czyni je dość atrakcyjnym celem dla ataków. Tak samo ważne jest odpowiednie zarządzanie dostępami. Testerzy powinni działać zgodnie z zasadą minimalnych uprawnień.
Strategie i techniki
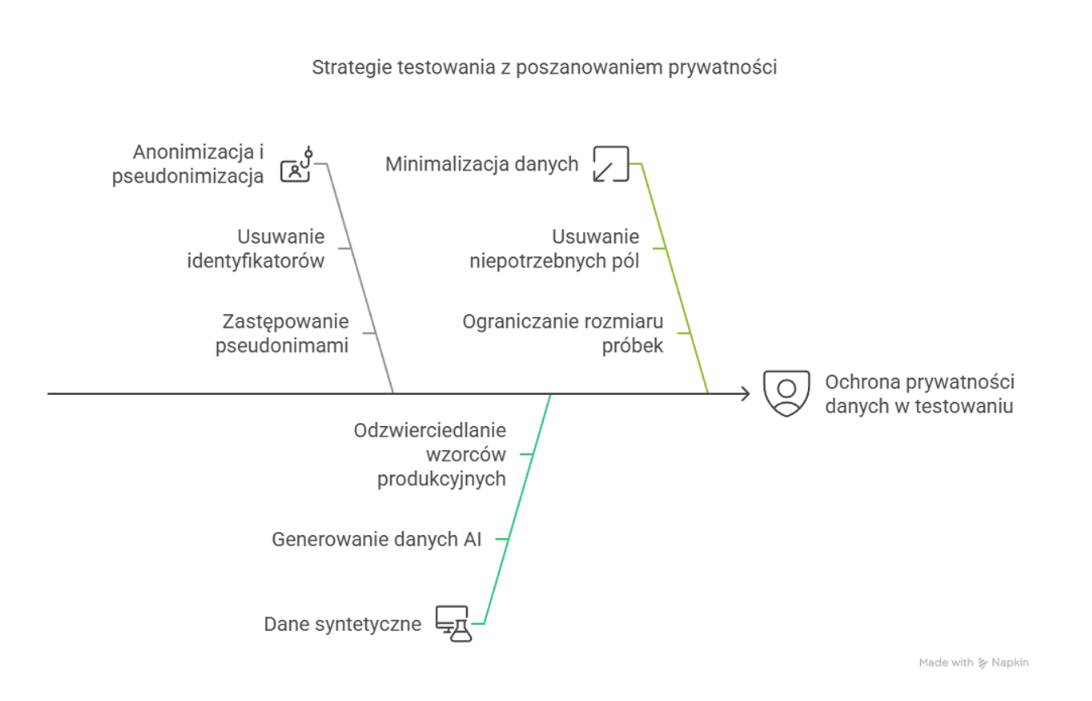
Skuteczne testowanie z poszanowaniem prywatności wymaga przemyślanej strategii i odpowiednich narzędzi. Omówimy tu trzy podejścia: anonimizacja i pseudonimizacja, wykorzystanie danych syntetycznych oraz minimalizacja zakresu danych testowych.
Anonimizacja i pseudonimizacja
Anonimizacja polega na trwałym usunięciu powiązań między danymi a osobą, której dotyczą. Gdy proces ten zostanie przeprowadzony prawidłowo, takie dane nie są już objęte RODO, co sprawia, że stają się bezpiecznym materiałem testowym. W praktyce stosuje się m.in. usuwanie bezpośrednich identyfikatorów (np. imion czy numerów PESEL), zmniejszanie precyzji danych (generalizacja) albo całkowite usuwanie ich wartości (supresja).
Pseudonimizacja polega na zastąpieniu danych identyfikujących pseudonimami, przy zachowaniu możliwości ich przywrócenia, np. za pomocą klucza szyfrującego. W odróżnieniu od anonimizacji, dane pseudonimizowane nadal podlegają przepisom RODO, ale łatwiej jest je wykorzystać w testach, bo zachowują strukturę oryginalnych danych.
Dane syntetyczne zamiast rzeczywistych
Użycie prawdziwych danych klientów w testach zawsze obarczone jest ryzykiem. Alternatywą są dane syntetyczne, które są generowane sztucznie, ale są na tyle realistyczne, że wiernie odwzorowują charakterystykę danych produkcyjnych. Dzięki technikom opartym na sztucznej inteligencji, dane syntetyczne mogą odzwierciedlać typowe wzorce bez ujawniania jakichkolwiek rzeczywistych informacji. To szczególnie sprawdza się w branżach takich jak bankowość czy opieka zdrowotna, gdzie każdy błąd w ochronie danych może mieć poważne skutki prawne.
Minimalizacja danych testowych
Zasada minimalizacji danych to jedna z podstaw RODO i praktyka, którą warto wdrożyć także w testowaniu. Chodzi o ograniczenie zakresu danych tylko do tego, co faktycznie jest nam potrzebne. W praktyce oznacza to m.in. usuwanie niepotrzebnych pól, ograniczanie rozmiaru próbek czy projektowanie scenariuszy testowych w taki sposób, by działały na minimalnym zestawie danych. To skutkuje mniejszym ryzykiem, niższym kosztem i szybszymi testami, ale żeby to działało, zespół testerski musi ściśle współpracować z analitykami, by dobrze określić, co naprawdę jest potrzebne.
Narzędzia i implementacja
Wdrożenie podejścia privacy-first w testowaniu wymaga zarówno odpowiednich narzędzi, jak i dobrze przemyślanych procesów. Zespoły testowe potrzebują rozwiązań, które zapewnią bezpieczeństwo danych testowych bez utraty elastyczności w pracy.
Narzędzia wspierające privacy-first testing
Nowoczesne platformy do zarządzania testami dają możliwość elastycznej konfiguracji od widoków i pól, po przepływy pracy. Najlepsze z nich bez problemu integrują się z popularnymi narzędziami do automatyzacji jak Selenium czy Cypress i systemami śledzenia błędów, np. Jira albo Bugzilla.
Jeśli mówimy o ochronie prywatności, szczególnie przydatne są narzędzia, które umożliwiają:
- generowanie danych syntetycznych,
- automatyczną anonimizację i pseudonimizację danych produkcyjnych,
- wykrywanie i maskowanie danych osobowych,
- bezpieczne przechowywanie danych testowych,
- monitorowanie zgodności z przepisami o ochronie danych.
Warto też zwracać uwagę na rozwiązania zintegrowane z pipeline'ami CI/CD, bo pozwalają one na automatyczne wykonywanie testów bez ryzyka ujawnienia danych. Ważna jest również możliwość raportowania (metryki dotyczące bezpieczeństwa danych powinny być dostępne od ręki).
Jak wdrożyć podejście privacy-first
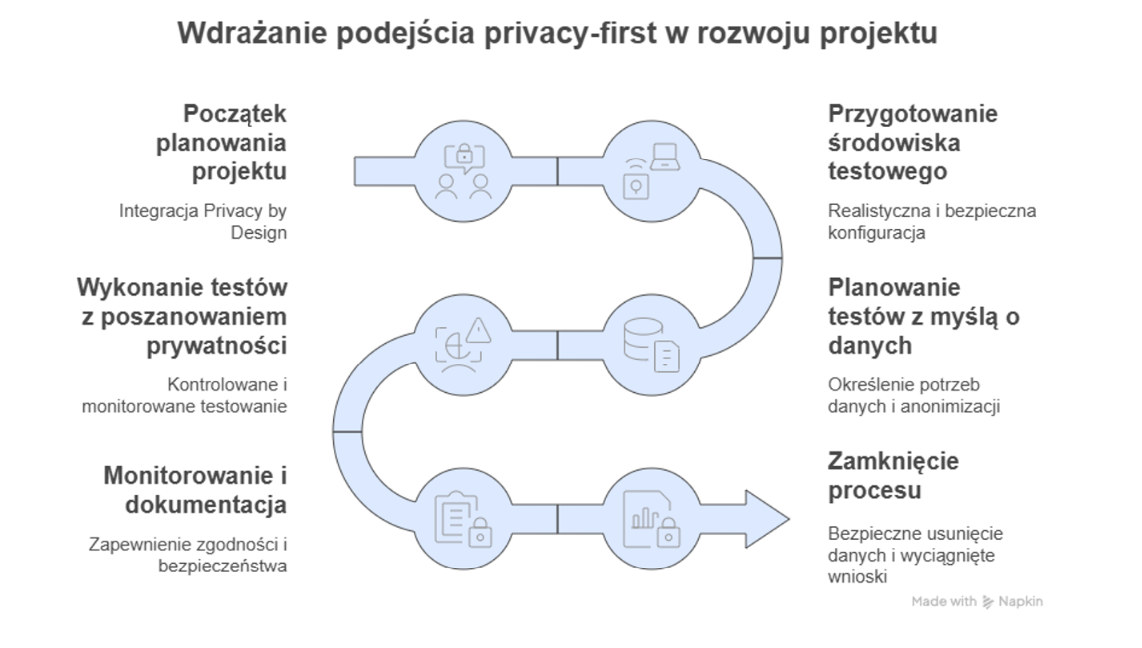
Prawidłowa implementacja powinna zacząć się już na etapie planowania projektu:
- Włączenie kwestii prywatności w cały cykl wytwórczy. Privacy-first powinno być obecne od samego początku, zgodnie z zasadą Privacy by Design. W metodykach zwinnych warto ująć aspekty ochrony danych w definicjach „gotowości” i „ukończenia” historyjek użytkownika.
- Przygotowanie odpowiednich środowisk testowych. Powinno ono być odseparowane od produkcyjnego, ale jednocześnie wystarczająco realistyczne. Konieczne są mechanizmy kontroli dostępu i monitorowania aktywności.
- Zaplanowanie testów z myślą o danych. Plan testów powinien jasno określać, jakie dane są potrzebne, jakie techniki anonimizacji będą stosowane i jak dane zostaną zabezpieczone oraz usunięte po zakończeniu testów.
- Dbanie o dane testowe. To moment na import danych produkcyjnych (jeśli już muszą się pojawić – tylko po anonimizacji) albo przygotowanie danych syntetycznych. Dane muszą mieć odpowiednią strukturę i zachowywać właściwości statystyczne oryginałów, bez ujawniania prawdziwych informacji.
- Wykonywanie testów z poszanowaniem prywatności. Realizacja scenariuszy testowych powinna odbywać się w środowiskach zbudowanych z myślą o ochronie danych – z kontrolą dostępu i bieżącym monitorowaniem.
- Monitorowanie i dokumentowanie. Sprawdzanie zgodności testów z wymogami ochrony danych, korzystanie z mierników i raportów, które pokazują realny stan bezpieczeństwa.
- Zamykanie procesu z głową. Po zakończeniu testów dane należy bezpiecznie usunąć lub zarchiwizować, a wnioski z testów uwzględnić w dokumentacji Lessons Learned - szczególnie te związane z prywatnością.
W tym wszystkim nie można zapominać o testach penetracyjnych. W kontekście danych powinny być obowiązkowym elementem procesu zapewnienia jakości, włączając w to rozpoznanie i skanowania, a także ostatnie elementy takie jak wykrycie podatności i raport z wynikami.
Wnioski
Podejście privacy-first w testowaniu realnie wpływa na bezpieczeństwo danych, reputację firmy i zaufanie użytkowników. Nawet jeśli dojdzie do naruszenia, dane nie są powiązane z konkretnymi osobami. Mniejsze ryzyko oznacza mniejsze straty reputacyjne, finansowe, operacyjne.
Ale takie podejście ma też wymiar ekonomiczny, bo zarządzanie bezpiecznymi danymi kosztuje mniej. Mniej wymagań dotyczących zabezpieczeń, mniej formalności, mniej stresu. Jest jeszcze jeden bonus: łatwiejsze dzielenie się danymi między zespołami czy partnerami zewnętrznymi. Anonimizacja eliminuje bariery formalne i otwiera przestrzeń na współpracę i innowacje. Firmy, które traktują prywatność poważnie, mają mocniejsze relacje z klientami i partnerami. A to w dłuższej perspektywie procentuje bardziej niż jakiekolwiek procedury.