Redakcja
Redakcja


Kontekst
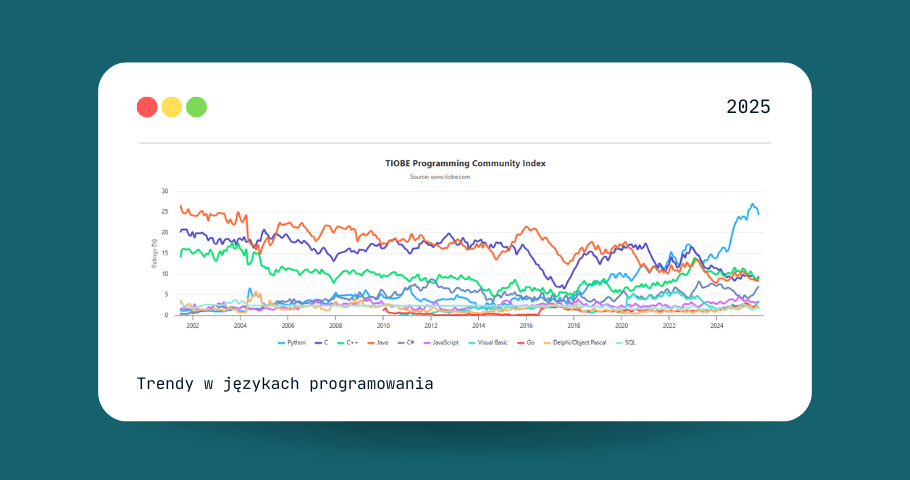
Rozwój modeli językowych sprawił, że AI coraz częściej wspomaga tworzenie kodu, testowanie, refaktoryzację czy debugowanie. W odpowiedzi na ich możliwości powstały systemy oparte na agentach, czyli złożonych środowiskach, w których model (np. GPT-4) wykonuje polecenia, analizuje wyniki, używa narzędzi (edytorów, terminali, frameworków testowych), a nawet planuje kolejne kroki. Przykłady? Devin, SWE-agent, AutoCodeRover.
Te podejścia próbują odwzorować sposób pracy ludzkiego programisty, ale same w sobie wprowadzają nowe problemy. Posiadają one kosztowne i trudne w utrzymaniu interfejsy z repozytorium, rozmytą logikę decyzji modelu i wykazują się trudnością w identyfikacji momentu, w którym „coś poszło nie tak”. Złożoność architektury działa tu na niekorzyść, bo każda interakcja z narzędziem to potencjalne źródło błędu, kosztów i nieprawidłowości.