Redakcja
Redakcja

Agenci AI mają ambicję wspierać inżynierię oprogramowania na każdym etapie cyklu życia oprogramowania. A jak jest naprawdę? Zespół Bismuth postanowił to sprawdzić, tworząc benchmark SM-100, próbę syntetycznego, ale realistycznego przetestowania kompetencji agentów AI w wykrywaniu i naprawianiu defektów. To ważna inicjatywa, choć niepozbawiona słabych punktów.
Co testuje SM-100?
Na wstępie warto podkreślić: SM-100 to benchmark skupiający się niemal wyłącznie na kodzie. Testowane są defekty obecne w repozytoriach open source, a nie na przykład problemy związane z wymaganiami, UX czy złożoną integracją. To ograniczenie zakresu trzeba mieć z tyłu głowy, szczególnie gdy mówimy o „pełnej automatyzacji” procesu utrzymania.
Druga sprawa: twórcy benchmarku są jednocześnie autorami jednego z testowanych narzędzi - agenta Bismuth. Trudno tu mówić o pełnej niezależności badawczej, choć trzeba uczciwie przyznać, że metodologia i kryteria oceny zostały opisane przejrzyście.
Struktura benchmarku
Zestaw testowy SM-100 obejmuje 100 zweryfikowanych defektów z 84 repozytoriów w językach Python, TypeScript, JavaScript i Go. Uwzględniono tylko defekty o jednoznacznych skutkach: błędy bezpieczeństwa i błędy logiczne powodujące awarie lub utratę danych. Zrezygnowano z oceniania: nowej funkcjonalności, refaktoringu oraz stylu kodu i formatowania. To dobry kierunek, bo pozwala ocenić realną skuteczność modeli w wychwytywaniu tego, co naprawdę ma znaczenie z punktu widzenia jakości systemu.

Cztery kategorie oceny
Agenci AI zostali przetestowani w czterech obszarach:
- Wykrywanie defektów bez podpowiedzi („igła w stogu siana”)
- Precyzja (redukcja liczby fałszywych alarmów)
- Wykrywanie defektów podczas code review
- Jakość proponowanych poprawek

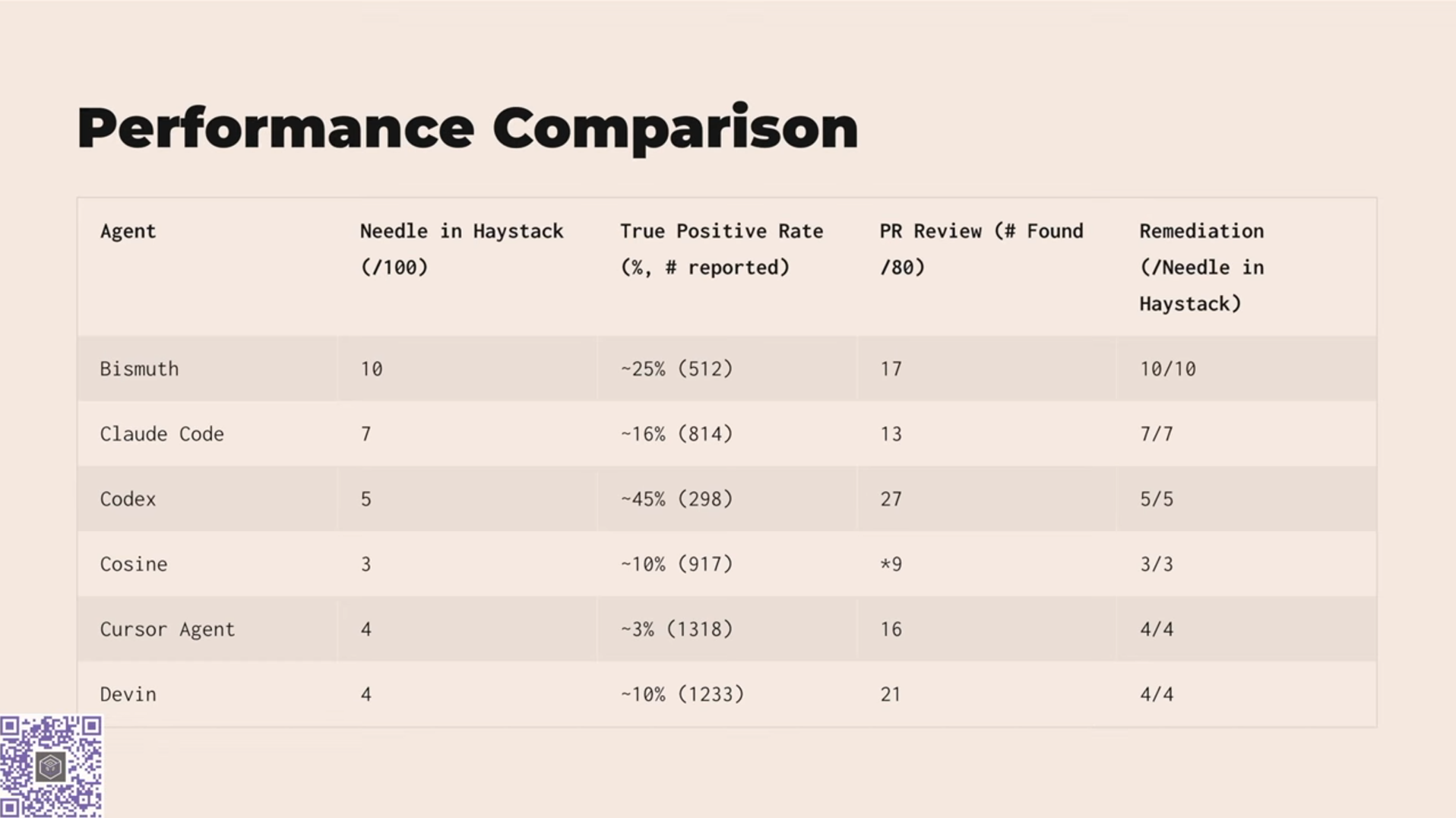
Na papierze brzmi dobrze. W praktyce wyniki pokazują, że do produkcyjnej gotowości jeszcze daleko. Najlepszy agent wykrył 10 na 100 defektów bez żadnych wskazówek. Średnia skuteczność najczęściej używanych agentów wynosi 7%. Dla porównania - człowiek, doświadczony programista, zauważyłby większość z nich w czasie klasycznego code review.


Jeszcze bardziej niepokojące są liczby dotyczące fałszywych alarmów. Niektóre modele wygenerowały po 900-1300 raportów na jeden problem, z czego zaledwie kilka procent miało sens. Jeden z agentów zaproponował aż 70 różnych „rozwiązań” dla pojedynczego defektu. Takie nadgorliwe podejście może utrudniać, a nie ułatwiać pracę.
Modele open-source na szarym końcu
W zestawieniu szczególnie słabo wypadają modele open-source. DeepSeek (R1) wykrył zaledwie 1% defektów. Llama Maverick - 2%. To może rozczarowywać, biorąc pod uwagę popularność i aktywność społeczności open source, ale jednocześnie stanowi ważny sygnał ostrzegawczy: sama dostępność modelu nie przekłada się automatycznie na jego jakość.

Słabe punkty klasycznych benchmarków - odpowiedź SM-100
Trzeba oddać autorom benchmarku, że podjęli próbę ucieczki od klasycznego podejścia znanego z narzędzi statycznej analizy kodu. Tamte testy skupiały się głównie na typowych błędach technicznych (null pointery, SQL injection, przepełnienia buforów), które można wykryć bez rozumienia głębszego kontekstu.
SM-100 stawia poprzeczkę wyżej. Celuje w realistyczne błędy wymagające kontekstowej analizy. To krok we właściwym kierunku, który może zachęcić branżę do dalszego rozwijania metod testowania AI.
Co trzeba poprawić w agentach?
Z raportu płynie jasny wniosek: dzisiejsze modele potrzebują głębszego zrozumienia systemu jako całości. Priorytety na najbliższy czas to analiza zależności między plikami, umiejętność wykrywania powtarzalnych wzorców defektów, lepsze skupienie na kluczowych fragmentach kodu, redukcja hałasu (czyli liczby błędnych zgłoszeń) oraz zdolność do eksploracji wybranych scenariuszy z większą precyzją. Bez tego agenci pozostaną narzędziami pomocniczymi - przydatnymi przy generowaniu kodu, ale zbyt zawodnymi, by powierzyć im zadania konserwacyjne.
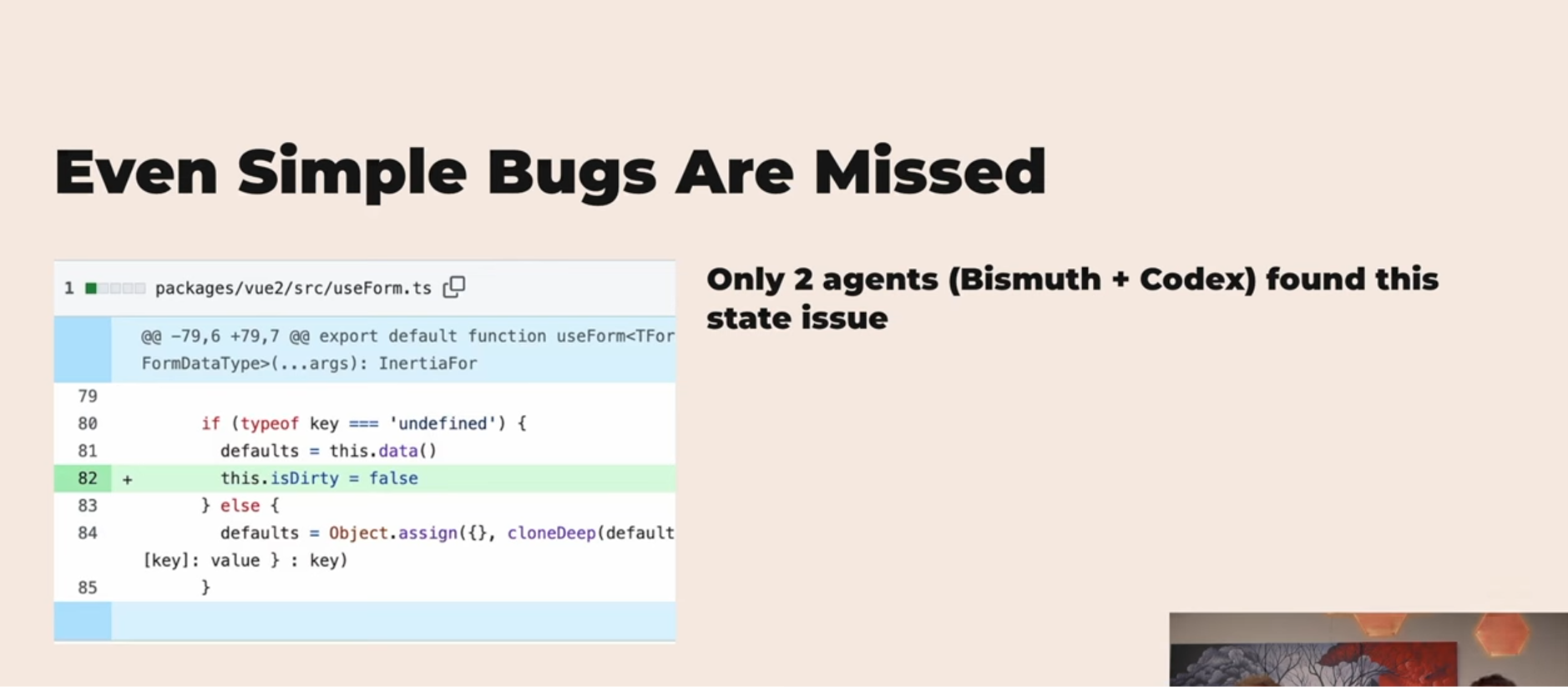
Benchmark SM-100 nie jest doskonały. Zawiera potencjalne źródła stronniczości, a jego zakres obejmuje wyłącznie defekty kodu. Mimo to warto go traktować jako ważny sygnał: agenci AI wciąż są na wczesnym etapie rozwoju. Ich praca nie przekłada się jeszcze na praktyczne zastosowania w zespołach deweloperskich.
Z drugiej strony, forma raportu, przejrzyste kryteria, konkretne dane i twarde liczby pokazują kierunek, w którym warto iść. Publikacje, których fundamentem są liczby, a nie hype, są dokładnie tym, czego dziś potrzebujemy w rozmowie o AI w testowaniu i utrzymaniu oprogramowaniu.
Pełną prezentację raportu można zobaczyć tutaj: https://www.youtube.com/watch?v=wAQK7O3WGEE
Więcej o SM-100: https://sm100bench.com