Ola Kunysz
Ola Kunysz


Mówi się, że rośnie to, co mierzymy. Jeśli mierzymy procent linijek kodu, dla których istnieje kod testowy, który je wywołuje, to urośnie nam liczba testów. To niekoniecznie musi iść w parze z jakością tych testów, ich wnikliwością i realizacją wszystkich przypadków biznesowych. Więc jak mierzyć jakość testów? No bo sama miara code coverage to chyba za mało? W kolei jednostka WTF/minute jest dość subiektywna.

Jak wykorzystywać code coverage?
Obliczanie procentowej ilości kodu, który został przetestowany stało się tak powszechne, że nawet edytory nie wymagają już dodatkowych wtyczek, ani bibliotek, bo mają tę funkcję wbudowaną. Wystarczy uruchomić testy i dostajemy wynik. Jednak ta jedna magiczna liczba nie jest najważniejsza, najważniejszy jest raport rozbity na moduły i klasy. To w nim możemy zobaczyć gdzie dzieje się najgorzej. Jeśli pokrycie kodu testami oscyluje gdzieś pomiędzy 20% a 80%, możemy te miejsca wstępnie odfiltrować i zostawić na później.
Najciekawsze na początku będą te, gdzie mamy 0%. To może oznaczać dwie rzeczy: nie mamy testów, bo jest je trudno napisać. Albo nie mamy testów, bo nikogo ten kod nie obchodzi. Tutaj wkracza największa supermoc miary code coverage – usuwanie zbędnego kodu. Jeśli gdzieś nie ma testów, a pisanie testów to raczej norma w naszym zespole, to jest duża szansa, że to miejsce zapomniane przez wszystkich można posprzątać. Jeśli tak nie jest, to warto być dobrym skautem i napisać kilka testów, pokrywając choćby najważniejsze scenariusze.
Line coverage vs branch coverage
Jeśli mamy już taki stan, że wszędzie są jakieś testy, możemy zacząć analizować dalej. Poza miarą line coverage (zazwyczaj używanej w domyśle jako code coverage) dobrze jest posłużyć się jeszcze branch coverage. Jest ona rzadziej stosowana i trudniejsza w obliczaniu. Jednak nieco lepiej oddaje dokładność naszych testów. Nie testuje pokrycia samych linii kodu, ale różnych scenariuszy, które są realizowane w kodzie. Na poniższym przykładzie widać warunek, który składa się z dwóch wyrażeń logicznych. Dla usatysfakcjonowania pierwszej miary, wystarczy, żeby kod wewnątrz bloku był wywołany. Dla drugiej, muszą być przetestowane wszystkie scenariusze, które mogą tutaj wystąpić.
void validateMessage(MsgInfo msgInfo) {
if (msgInfo.hasEmptySubject() || msgInfo.hasEmptyRecipient()) {
throw new InvalidEmailException("Empty fields not allowed");
}
if (emailAddressIsIncorrect(msgInfo)) {
throw new InvalidEmailException("Email address of recipient invalid");
}
}
Line coverage – 80%
Branch coverage – 33%
Widać od razu jak drastycznie wyniki różnią się w przypadku posiadania tylko jednego testu, który sprawdza pierwszy lepszy scenariusz. Warto wprowadzić miarę branch coverage do swoich metryk. Większość edytorów pozwala na jej stosowanie, jednak nie jest to tak oczywiste.
W IntelliJ IDEA włączysz generowanie raportu poprzez zmianę Sampling na Tracing w ustawieniach: (Run | Edit Configuration | JUnit > Code Coverage)
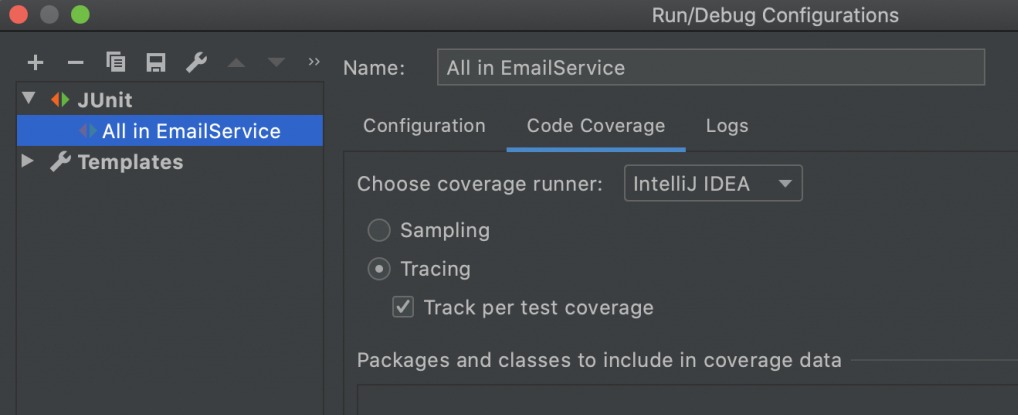 Potem wystarczy uruchamiać testy z pomocą Run with Coverage zamiast zwykłego Run, a uzyskamy raport podobny do tego:
Potem wystarczy uruchamiać testy z pomocą Run with Coverage zamiast zwykłego Run, a uzyskamy raport podobny do tego:
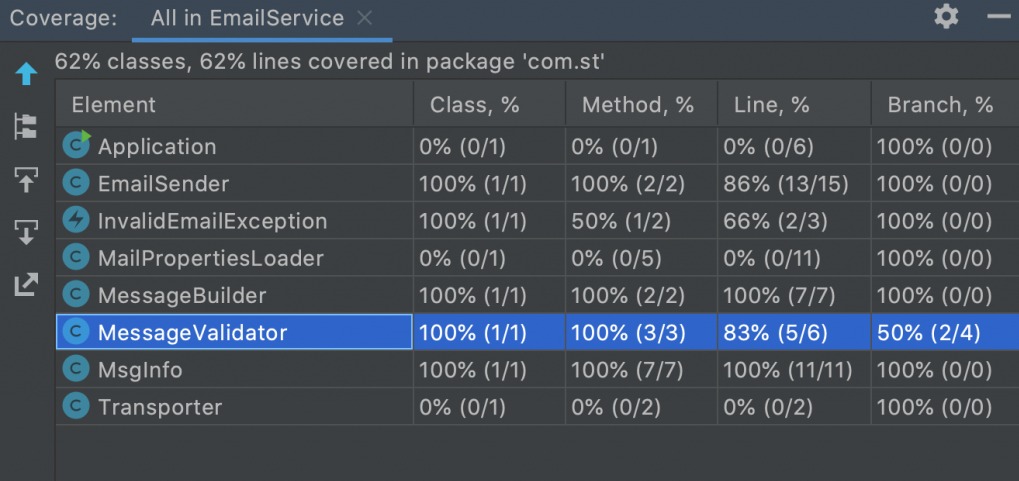
Czy testy odeprą atak mutantów?
Innym momentem rozczarowania naszymi testami może być wprowadzenie testów mutacyjnych. To wprowadzanie „złośliwych” zmian do naszego kodu i sprawdzanie, czy nasze testy to wyłapią. Takie testy to prawdziwa wojna. Za każdym razem, kiedy testy wykryją regresję, mutant zostaje zabity. Jeśli przeoczą mutanta, zagnieżdża on się w kodzie i zadaje cios. Wynik tych testów to taki krajobraz po bitwie. Można go wykorzystać do poprawiania testów, tam gdzie testy przegrały z kretesem. Dla mojego serwisu w Javie użyłam PIT’a, który wykonuje testy mutacyjne i generuje raport za każdym razem, kiedy uruchamiam.
mvn clean test
Przykładowy raport testowy wygląda tak:
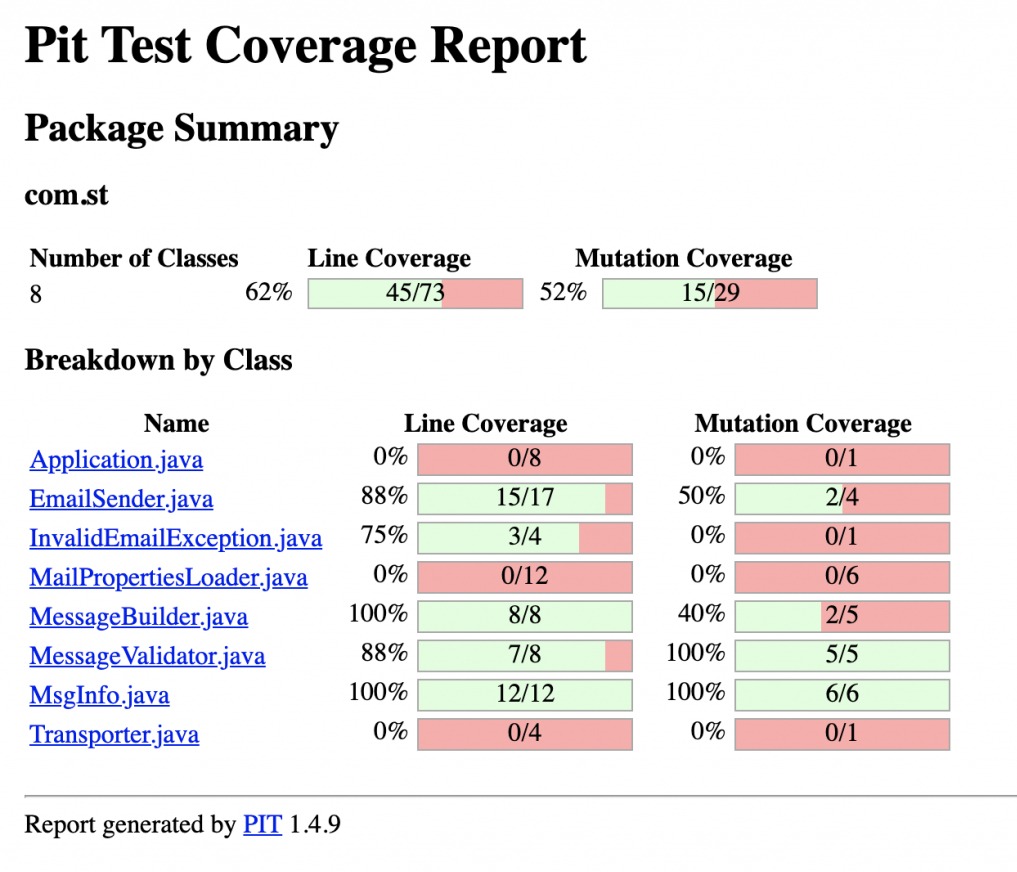 Dla całej aplikacji wynik testów mutacyjnych jest nieco niższy. Dla niektórych kawałków kodu to przepaść! Co ciekawe, dla mojej niedokładnie przetestowanej logiki, testy mutacyjne były bardziej łaskawe niż samo pokrycie kodu testami.
Dla całej aplikacji wynik testów mutacyjnych jest nieco niższy. Dla niektórych kawałków kodu to przepaść! Co ciekawe, dla mojej niedokładnie przetestowanej logiki, testy mutacyjne były bardziej łaskawe niż samo pokrycie kodu testami.
 To dlatego, że testy mutacyjne bardziej drążą tutaj warunki logiczne, niż sprawdzają co dzieje się po ich sprawdzeniu.
To dlatego, że testy mutacyjne bardziej drążą tutaj warunki logiczne, niż sprawdzają co dzieje się po ich sprawdzeniu.
Jak widać, różne narzędzia do oceny naszych testów będą dawać różne wyniki. Warto patrzeć na różne metryki, bo jedna nigdy nie da nam obiektywnego obrazu. Warto też traktować je bardziej jako podpowiedź do pisania lepszych testów, niż wyrocznię.